1. Ensuring an uninterrupted supply of high-quality building materials to construction organizations;
2. Normalization of inventory and optimization of the construction organization’s own working capital.
Initial data that is necessary to develop a materials requirements plan:
3). Information on the state of the construction market and prices for materials;
4). Information on the capacity of own auxiliary production;
5). Data on actual balances of materials at the end of the year;
6). Production standards for materials consumption (EPEP);
7). Local estimates for each object for which applications are drawn up.
Planning for the need for materials is carried out for each object separately, then a consolidated plan for material and technical support is drawn up.
| No. | Name materials, structures | Demand by flow direction | Inventories at the end of the pre-planned year | Remaining and total requirement | Coverage sources | ||||||||||||
| contractors personal work forces | subcontracting work | utility room | repair and maintenance | for events technical development plan | other needs | Total | supplies by agreements | customer supplies | auxiliary production | savings according to the technical development plan | balances at the end of the year | Total | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
Basis for determining the need for building materials
are production consumption standards that are developed in the context of individual types of construction and installation work.
In the absence of all the necessary information on objects, the use of estimate standards is allowed.
Materials are also purchased from wholesale stores and building materials stores.
Inventory planning.
The main purpose of supplying enterprises is to ensure uninterrupted supply of materials.
The main focus should be on reducing overall materials costs.
To reduce costs, a targeted policy of corporate logistics management is required, including a set of measures:
1. Improving demand planning and rationing the costs of material resources;
2. Elimination of losses from defects in production and losses in material resources during delivery;
3. Maximum reduction of production waste and its recycling;
4. If possible, eliminating intermediate storage of material resources when delivering them from the supplier;
5. Optimization of the level of inventories of material resources.
Inventory management is a key component of logistics management. Inventories, as an economic category, play an important role in the production and circulation of products. However, inventories play both a positive and negative role, both in the economy as a whole and for an individual organization.
The positive role is that they ensure continuity of the production process.
The negative side is that they freeze significant financial resources and volumes of inventory.
In connection with the above, inventory planning is relevant.
Inventories consist of current stock, preparatory stock, warranty stock and seasonal stock.
Total stock:
Z = Zt + Zp + Zch + Zs [day, natural. units]
The current stock (3t) is provided to ensure uninterrupted progress of construction between two next deliveries (maximum three days).
Preparatory stock (Zp). Its norm = the minimum required period to prepare received materials for use in production.
The safety stock (SG) is provided to ensure uninterrupted operation in the event of a failure of the next delivery (50% of the current stock).
Seasonal reserves (SS) are created in remote individual organizations (regions of the Far North, etc.). Created for the entire period of thaw. His total need = number of days of mud * volume of materials.
Planning sources of coverage for material needs.
The sources of covering the need for construction materials are the following:
1. Deliveries directly from manufacturers;
2. Deliveries through intermediary supply organizations;
3. Customer deliveries.
4. Products from our own subsidiary production facilities;
5. Balances at the beginning of the year.
Ozh = Of + Pozh – Rozh,
whereOf – actual balances as of the date of the report;
Pozh – expected supplies of materials;
Rye – expected consumption of materials.
Зп = Рп + Нз – Ож,
whereZp is the amount of materials to be procured in the planning year;
Рп – planned consumption of materials in the planned year;
NZ – norm of carry-over stocks;
Оож – expected balances.
Materials cost planning.
Since materials in terms of costs occupy the most specific weight in the cost structure, planning is quite relevant.
Material costs are determined based on the actual need and unit price of the material.
Mz = åMip*Cim
where Mip is the need for materials
Cim is the price of the material.
The difficulty of determining the price of a material is due to the following reasons:
1. The need to calculate prices;
2. Price changes in a short time.
The need to calculate prices is due to the fact that the costs of materials consist of several costs:
1. costs of purchasing materials;
2. costs of transporting materials;
3. costs of packaging, containers;
4. procurement and storage costs.
To take into account price changes, it is necessary to trace the price dynamics of the defining year, and using these data, try to predict the planned price of a particular type of material.
1.2.4 Labor and payment plan
The main objective of the labor and personnel plan is to ensure the rational, effective use of enterprise personnel in the manufacturing process.
The initial data for drawing up a labor plan are:
· long-term plan for the development of the enterprise;
· results of product market research;
· results of analysis of the production and economic activities of the enterprise for the previous period;
· legislative acts and other regulatory documents of an all-Russian and industry nature on issues of wages, social protection of the population, as well as industry standards of time and output for printing production processes as recommendations.
Personnel or labor resources of an enterprise are a set of employees of various professional and qualification groups employed at the enterprise and included in its payroll. The payroll includes all employees hired for work related to both core and non-core activities.
Labor resources are the main resource of an enterprise, the quality and efficiency of its use largely determine the results of the enterprise’s activities and its competitiveness. Labor resources set in motion the material elements of production, create product, value and surplus product in the form of profit.
The labor and personnel plan includes the following sections:
1. Planning for labor productivity growth.
2. Planning the number of employees.
3. Planning of the wage fund.
4. Planning for advanced training of enterprise employees.
Let's look at each section separately.
Planning for labor productivity growth
The growth of labor productivity is one of the central economic issues at all levels of production management.
Labor productivity is characterized by the number of products (volume of work performed) produced by one employee (worker or worker) per unit of working time, or its inverse indicator of labor intensity, which is characterized by the amount of working time (man-hour) spent on the production of one accounting unit of production.
The system of indicators (measurements) of labor productivity is formed depending on the following factors:
· product volume meter (natural or cost indicators);
· units of working time (year, quarter, month, day, hour);
· the number of employees that are taken into account when planning.
Accordingly, depending on the measurement of production volume, three types of labor productivity indicators are distinguished:
1) group of cost indicators;
2) a group of natural (physical and conditional) indicators;
3) labor meters (standard hour, man-hour).
Cost indicators are universal, are currently determined through contract prices, are influenced by inflation and do not very clearly characterize real labor productivity.
Natural indicators, in turn, have limited use; they are used in drawing up plans for enterprises (main workshops and sections), are not affected by inflation, and give a factual idea of labor productivity in the manufacture of a specific type of product.
Labor meters characterize the dynamics of labor productivity in a specific operation. In this case, the standardized labor intensity of manufacturing a certain volume of products (unit) is divided by the planned or actual labor costs for the production of the same volume of products. This is the most accurate measure of labor efficiency, but has limited use.
Depending on the number of workers taken into account when planning labor productivity, indicators are distinguished per one employee of industrial production personnel and per one production worker (main or auxiliary).
Depending on the unit of working time, the following types of labor productivity are distinguished: annual, quarterly, monthly, ten-day, daily, shift and hourly.
Hourly labor productivity can be considered the most accurate. Daily depends on hourly productivity, as well as on the duration of the shift in hours and intra-shift loss of working time. Monthly labor productivity is influenced by the daily productivity and the number of working days planned to be worked during the month per worker (or employee), therefore, the more daily absenteeism (loss of working time), the lower the monthly labor productivity. Annual productivity is always less than monthly productivity multiplied by 12 months (this occurs due to regular vacations of workers). Thus, this group of labor productivity indicators is based on two factors:
hourly labor productivity;
· the number of hours worked by one employee per year.
Let's take a closer look at each of these factors.
Hourly labor productivity is the main indicator of labor efficiency, which depends on:
· level of mechanization and automation of production;
· technology used;
· quality of raw materials and materials;
· qualifications of workers;
interest in work;
· working and production conditions.
Accordingly, in order to increase labor productivity at an enterprise, it is necessary to take some steps, namely: increase the technical level of production; improve the organization of production, labor and management; improve the product range and range; improve product quality (elimination of defects and their prevention); take into account the social factor influencing the labor incentive system and other industry and non-industry factors.
To use real opportunities to increase labor productivity, it is necessary to develop a complex that would change the factors of production conditions. At the same time, measures of various content (technical, organizational and others) affect either a decrease in the labor intensity of products (reserves for reducing labor intensity) or a deterioration in the use of working time (reserves for working time). The intensive way to increase labor productivity by reducing the labor intensity of manufacturing products is practically limitless. Extensive factors are less effective and quite limited, since the calendar, routine and nominal working time funds are limited.
When drawing up a plan to increase labor productivity, the entire sum of indicators is calculated, namely:
· average annual labor productivity (by dividing the planned volume of production in the appropriate units of measurement by the planned average monthly number of employees);
· average monthly labor productivity (by dividing the annual planned volume of production by the number of man-months planned to be worked);
· average daily labor productivity (by dividing the planned volume of production by the number of man-days planned to be worked);
· average hourly labor productivity (by dividing the planned volume of production by the number of man-hours according to the plan).
Planning the number of employees
To plan the number of employees, it is necessary to know their composition at an industrial enterprise. Industrial production personnel (IPP) includes managers, specialists, office workers, workers (main and auxiliary).
In addition to the PPP, there is non-industrial personnel, together with whom the total number of employees is determined. Non-industrial personnel do not produce products, but help solve production issues. Of the total number, non-industrial personnel make up 3-7%.
The PPP is 95-97%, among which workers - 70%, office workers - 9-11%, specialists - 13-17%. In the structure of workers, main workers make up 70%, and auxiliary workers make up 30%.
The company's employees include non-scheduled employees. Their number is not planned, only the wage fund is planned, which can be allocated.
The time available for one worker per year depends on working conditions, planned absences (due to illness - planned for the previous period, related to the performance of government duties) and the duration of vacation.
Payroll planning
In order for an enterprise to be highly productive, the manager must be able to coordinate the efforts of many people and jointly realize the potential capabilities of employees. This can only be achieved if they are treated fairly. One of the components of such a relationship is fair remuneration, the most important and decisive element of which is wages. Wages are part of the fund for individual consumption of material goods and services, which goes to workers in accordance with the quantity and quality of work, as well as its effectiveness. It represents the amount of cash payments and the value of payment in kind for work performed under an employment contract. Wages are aimed at rewarding employees for work performed (services sold) and at motivating them to achieve the desired level of productivity.
The basis of the wage fund is the wage fund of industrial workers. It is considered when drawing up a plan for each workshop, taking into account the number of main industrial workers, category and the number of hours of production work planned to be worked during the year. In this case, wages are calculated based on the planned hours for the year. Then these hours are multiplied by the hourly tariff schedule of the corresponding category established at the enterprise. The result is a direct wage fund for the main and auxiliary workers employed in the main technologically regulated operations. This direct wage fund is the basis of the total (annual) wage fund of industrial workers.
The use of standard hours of production work in the calculation, rather than planned hours, is due to the fact that workers, exceeding the standard, must receive a larger direct wage. When calculating the number of main industrial workers, the planned hours of work required to complete the industrial program for the year are taken into account. This takes into account the influence of the growth factor in labor productivity due to a decrease in the number of workers.
The direct wage fund is also called the tariff fund. Its share in the annual total wage bill of workers is an important economic indicator. The higher this share, the greater the dependence of the wage fund on the volume of output and labor productivity of workers.
Let's consider what the hourly, daily, monthly and annual wage funds of workers consist of.
The hourly fund consists of the wage fund, calculated in hours, plus additional payments. These include surcharges for technological shutdowns, surcharges for inspections and downtime of equipment under repair (taking into account downtime and the hourly tariff rate of the time worker), bonuses, surcharges for team management for non-exempt foremen, surcharges for training students by skilled workers, surcharges for work in night time.
The daily fund is the wage fund calculated in days. It consists of an hourly fund and additional payments to the daily fund (i.e. payment for the time the teenager’s work is cut, etc.).
The monthly fund is calculated based on the daily fund plus additional payments up to the monthly fund. The annual fund is obtained by multiplying the monthly fund by eleven and adding the appropriate additional payments. This may include payments for basic and additional regular leave, educational leave, and absences due to the performance of government duties.
Developing salary structures is the responsibility of human resources departments, planning departments, or human resources services. An organization's wage structure is determined through analysis of a wage survey, labor market conditions, and the organization's productivity and profitability.
More than half of all employee income comes from the guaranteed or basic salary. Its size depends on a number of factors: position held, length of service at the enterprise, quality of the employee’s work. All these factors reflect the employee's skill level, experience and maturity.
In addition to salary, additional benefits are planned, and these additional payments constitute a significant part of the remuneration package paid by the organization.
1.2.5 Cost and profit plan
The cost of construction and installation works is the costs of a construction organization for their production and delivery to the customer. Planning the cost of construction and installation work is an integral part of the planning system of a construction organization. The purpose of planning the cost of construction and installation works is:
1. Determination of costs for carrying out work within the deadlines set by the customer with the efficient use of all types of resources.
2. Determination of profit and opportunities for production and social development of a construction organization based on the amount of profit remaining at its disposal.
3. Organization of intra-company economic accounting for a division of a construction organization.
The initial data for developing a cost plan are:
1). Manufacturing program;
2). Technical development plan;
6). Labor plan.
Estimated cost = cost + standard profit (planned savings)
The planned cost of construction work is determined using approved norms and standards, as well as engineering and economic calculations, reflecting an increase in the level of production as a result of the implementation of measures.
The cost of construction work carried out by a construction organization on its own consists of costs associated with the use of materials, fuel, electricity, fixed assets, labor and other costs in the production process.
The estimated cost is determined on the basis of estimated standards and corresponds to the amount of funds that the contractor receives from the customer.
The planned cost can be determined by 3 methods:
1. Calculation of the cost of construction work or structural elements.
2. Subtracting planned savings from the estimated cost and planning to reduce costs through the implementation of organizational measures.
3. Planning to reduce the cost of construction and installation work based on the actual level of the previous year (this method is used most often).
Actual cost is defined as the amount of costs actually incurred during construction and installation work. If the actual cost< сметной себестоимости, то строительная организация имеет прибыль.
Composition and classification of costs included in the cost of construction and installation work.
There are several signs of cost classification:
1. Depending on the time of occurrence of costs, they are divided into:
Current;
One-time.
2. Depending on the methods of including costs, they are divided:
Indirect (overhead).
3. Depending on the impact on the volume of work, costs are divided:
Permanent;
Variables.
4. Depending on the method of inclusion, costs are divided into elements and items.
Material costs are determined based on the need for materials based on the physical volume of work, norms and standards.
Labor costs are determined based on the wage funds of employees minus the wages of workers employed in auxiliary and auxiliary production, as well as minus wages not attributable to cost (bonuses).
Contributions for social needs are determined from mandatory contributions according to the norms established by law.
Depreciation is determined based on the average annual cost of fixed assets, on which depreciation is charged and the average rates of depreciation charges for the complete restoration of fixed assets.
Other costs add up:
Loan payments;
Payments for compulsory state insurance of enterprise property;
Travel expenses;
Costs of operating machines and mechanisms.
1. Costs of remuneration for workers servicing machines and wages of line personnel, subject to their inclusion in the team.
2. Costs of fuel, energy, steam.
3. Costs of all types of repairs and technical support.
4. Depreciation charges for full restoration.
5. Rent.
6. Relocation costs.
7. Costs of using and repairing crane tracks.
8. On-site transportation costs.
Overhead costs have 5 items:
1. Administrative expenses.
1.1 Remuneration of administrative and management personnel, MOP, security.
1.2 Deductions established by law.
1.3 Office expenses.
1.4 Utility costs.
1.6 Printing costs.
1.7 Costs of compensation for the use of personal transport of employees for business purposes.
1.8 Travel expenses.
1.9 Costs for all types of repairs.
2. Services for workers in construction.
2.1 Costs associated with training and retraining of personnel.
2.2 Costs of paying scholarships to students sent by the enterprise to educational institutions.
2.3 Expenses to ensure sanitary, hygienic and living conditions: maintenance of cabins, cleaners, electricians, mechanics.
2.4 Security and safety expenses.
2.5 Costs of maintaining premises provided to catering establishments.
3. Costs of organizing work on construction sites.
3.1 Costs of wear and tear and repair of equipment.
3.3 Costs for geodetic work (site breakdown).
3.4 Costs for designing the work.
3.5 Laboratory maintenance costs (a thing of the past).
3.6 Expenses for the maintenance and improvement of construction sites.
4. Other overhead costs.
4.1 Payments on bank loans.
4.3 Payments for compulsory insurance.
5. Costs not taken into account in the overhead rate, but included in overhead expenses.
5.1. Benefits paid to employees based on court decisions in connection with loss of ability to work.
5.2. Taxes, fees, payments and other mandatory deductions established by law.
5.3. Costs of organizing work on a rotational basis.
Methods for planning the cost of construction work
Planning of the cost of construction and installation works by cost items is carried out on the basis of calculations of the economic effect from the implementation of organizational and technical measures that ensure a reduction in cost in the planning year. The savings amounts calculated by element and by item must be equal. For detailed planned cost calculations, construction organizations can use various cost planning methods:
1. Regulatory;
2. Direct object-based calculation;
3. By factorial.
The construction organization sets its own planning procedures and methods.
The normative method is based on progressive production planning standards for calculating materials, wages, and operating time of machines and mechanisms (EPEP).
The method of direct object-based calculation is based on subtracting planned savings and cost reduction from the estimated cost of construction work. It is also based on the preparation of cost estimates for all types of work for each object separately. When preparing cost estimates, it is necessary to calculate costs for all cost items.
According to the factorial method. When planning cost using the factorial method, it is necessary to take into account the influence of all factors (both external and internal) on the cost of production.
CONCLUSION
The following conclusions were obtained from this study:
1.Technical and economic planning is a system of calculations for the development of plans for the technical, economic, organizational and social development of enterprises, aimed at fulfilling government orders and consumer orders in the corresponding planning period;
2. Includes a set of plans for various areas of the enterprise’s activities, namely a plan for production and sales of products, organizational and technical development, logistics, a plan for labor and its payment, cost and profit;
3. The plan for production and sales of products determines the production program of the organization and is the leading section of planning the company’s activities;
4. The technical development plan ensures through its measures an increase in production efficiency. The initial data for its compilation are:
Manufacturing program;
Information base for the region or for Russia as a whole
Title list of construction of a planned year facility
5. Labor resources are the main resource of an enterprise, the quality and efficiency of its use largely determine the results of the enterprise’s activities and its competitiveness.
6. The labor plan includes sections: planning for labor productivity growth, planning the number of employees, planning the wage fund, planning for advanced training of enterprise employees.
7. The purpose of planning the cost of construction and installation work is:
Determination of costs for carrying out work within the deadlines set by the customer with the efficient use of all types of resources;
Determination of profit and opportunities for production and social development of a construction organization;
Organization of in-house financial accounting for a division of a construction organization.
8. The initial data for developing a cost plan are:
1). Manufacturing program;
2). Technical development plan;
3). System of norms and standards (EREP)
4). Results of cost analysis for the previous period;
5). Information on prices and tariffs, and the dynamics of their changes;
6). Labor plan.
9. Planned cost can be determined by 3 methods:
compiling cost estimates for construction work or structural elements; subtracting planned savings from the estimated cost and planning to reduce costs through the introduction of organizational measures; planning to reduce the cost of construction and installation work based on the actual level of the previous year (this method is used most often).
BIBLIOGRAPHY
1. Strategic planning in an enterprise: textbook / T.P. Lyubanova, L.V. Myasoedova, Yu.A. Oleynikova.- M.: March, 2009.- 400 p.
2. Analysis of the financial and economic activity of an enterprise: textbook / Lyubushin N.P., Leshcheeva V.B., Dyakova V.G. -M.: UNITY-DANA, 2001.
3. http://www.planstroi.ruPlanstroy. Organization of production.
4. Enterprise planning: textbook / Kobets E.A. - Taganrog: TRTU Publishing House, 2006.URL:http://www.aup.ru/books/m160/1.htm
5. Planning at an enterprise: lecture notes / Makhovikova G. A., Kantor E. L., Drogomiretsky I. I. – M.: EKSMO, 2007. - 140 p.
6. Strategic management. Enterprise planning: textbook / Stepanova G.N. URL:http://www.hi-edu.ru/e-books/xbook097/01/index.html?part-003.htm#i107
7. Planning of production and economic activities of the enterprise. URL:http://www.cis2000.ru/cisBudgetingTwo/handbookD.shtml
8. Economic dictionary. Financial and economic terms and concepts. URL:http://www.ekoslovar.ru/278.htm
9. Enterprise planning /Maria Vasilchenko. URL: http://www.fictionbook.ru/author/mariya_vasilchenko/planirovanie_na_predpriyatii.
Used to pay for production assets is planned at 1.5% per quarter or 6% per year of their value. 1.10. The procedure for filling out Form 13 and calculating the main technical and economic indicators of the workshop. Indicators calculated earlier are entered into Form 13 from other forms. Reporting indicators are calculated. 1.Production. 1.1. Standard-clean products: ...
The concept, methods and means of ensuring business continuity (Business Continuity Planning - BCP) and business recovery after disasters (Business Disaster Recovery - BDR) are widely known and tested in the West. Emergency business continuity technology is an integral part of the operations of large companies and government organizations, allowing them to ensure virtually uninterrupted operations in the event of small- and medium-scale emergencies and restore their operations with minimal, pre-calculated losses in the event of large-scale disasters.
B.D. Alterman, V.I. Drozhzhinov, G.E. Moiseenko
Jet Info Online No. 5 2003
Readers of the article will become familiar with the terminology and basic concepts in the field of knowledge under consideration and the methodology for developing business continuity plans in emergency situations. Examples of specific plans are given.
Business continuity planning is a constant concern of the first leaders of organizations and companies who do not live by the day and are interested in the preservation and development of their enterprises. This article is primarily intended for them and those responsible for the safety and financial health of companies and organizations.
One of the authors of the article, V.I. Drozhzhinov is a certified Business Continuity Planning Specialist (ABCP), he was trained in Canada at the Institute for Disaster Recovery and passed the certification exam. The certificate was issued by the International Institute for Disaster Reconstruction (New York, USA).
Introduction
Abnormal or emergency situations are understood as external influences that lead to the impossibility of the enterprise functioning in the usual mode regulated by the relevant standards of the enterprise.
Such external influences primarily include:
- Power outage
- Picketing and strikes
- Water or sewerage breaks
- Terrorist acts or threat thereof
- Failure of air conditioners
- Civil unrest
- Fires
- Local conflicts
- Natural disasters
In addition to direct losses, organizations incur costs associated with violation of production and financial accounting procedures, loss of customer favor, deterioration of image and decreased competitiveness.
The concept, methods and means of ensuring business continuity and recovery after disasters (Business Continuity Planning - BCP and Business Disaster Recovery - BDR) are widely known and tested in the West in the event of officially declared disasters and emergencies of a smaller nature. They are an integral part of the operations of many large companies, allowing them to ensure virtually uninterrupted operations in the event of small- and medium-scale emergencies and restore their operations with minimal, pre-calculated losses in the event of large-scale disasters.
In order to protect yourself in case of emergency situations, you need to have:
- Contingency plan
- Well-trained and trained "emergency teams".
An organization's business continuity plan is a detailed list of activities that must be completed before, during, and after an emergency or disaster. This plan is documented and tested regularly to ensure that in the event of an emergency, it will ensure that the organization can continue to operate and have critical resources in reserve.
Having even a very good plan will not guarantee a company's protection from trouble unless it has well-trained teams of employees who know what, when and how they should do if any emergency occurs.
Analysts note that losses from the Sept. 11 terrorist attack could have been significantly greater if the contingency plans that most U.S. companies had in place had not been in place. Note that many of these plans appeared in anticipation of the year 2000 in connection with the so-called “Problem 2000” ().
Table 1. Companies' actions to improve security in the lead-up to 2000 and after September 11, 2001.
|
ACTIONS |
||
|---|---|---|
|
ON THE EVE OF 2000 |
||
|
Cyber threats to organizational systems |
The IT industry has created tools to detect and fix Year 2000 (Y2K) problems in hardware and software. Companies have incurred significant costs to test, modify and replace their systems |
There are a huge number of technical solutions to ensure security, and careful selection is required in each specific case. It should be borne in mind that the safety of people is no less important than the safety of material assets. |
|
Commercial dependence and interdependence of companies |
Various industrial associations have assessed the threat of supply chain disruptions and the consequences of such disruptions. Companies required their suppliers to confirm that their information systems had eliminated Y2K-related threats. |
Companies have increased their awareness of supply chain sustainability issues. After 9/11, they began to rely less on just-in-time deliveries and more on just-in-case inventories. |
|
Cyber threats to critical infrastructures |
Owners and operators of infrastructure (telecommunications, pipelines, etc.) have addressed the Year 2000 problem in their systems, developed and tested their post-disaster recovery plans, and created collaborative networks to share information and coordinate emergency response |
Companies exchange information very sluggishly in all areas except financial, where there are long-term trusting relationships that allow coordinating actions in emergency situations |
|
Reluctance to share information |
The US Congress passed a law according to which the exchange of information between Companies on the "Problem 2000" is not a violation of antitrust laws |
Currently, the US Congress is considering a law on the exchange of anti-terrorism information between companies, similar to the law adopted in relation to Problem 2000. |
|
An atmosphere of fear and uncertainty |
Enterprises and their associations organized a press campaign to convince shareholders and the public that the consequences of the Year 2000 Problem would be minimal |
Immediately after September 11, all companies publicly expressed condolences to the relatives of those killed in the WTC buildings |
|
Planning horizon |
Knowing the exact date of the Year 2000 Problem and understanding its essence simplified the planning of work to overcome it. The presence of the necessary tools led to a reduction in the time required to solve the problem |
The timing of a terrorist attack and the means used are unpredictable. Therefore, a thorough risk study is necessary to determine appropriate protective measures and tools. |
Are Russian companies ready to implement business continuity plans? Information about this is contradictory. Study of the IT services market conducted by Market-Visio/EDC in 2000-2001. (http://www.edc.ru/), showed that the business continuity planning (BCP) service in Russia is still in little demand.
A 2001 study by Ernst & Young (www.ey.com/Russia/security-risk) indicates that 67% of Russian companies surveyed have business continuity plans (BCP), with 61.2 % of these companies have tested their plans, while 38.8% have not.
Such different estimates are explained by the fact that Market-Visio/EDC surveyed enterprises on the issue of business continuity in the face of complex threats (see), and Ernst & Young, judging by the contents of the report, only on information security problems (computer failures, hacker attacks, computer viruses, etc.).
Table 2. Classification of business interrupters (risks) (not exhaustive)
|
BUSINESS INTERRUPTER TYPE |
ENGLISH NAME OF THE BREAKER |
RUSSIAN NAME OF THE BREAKER |
|---|---|---|
|
Entrepreneurial |
Business Relocation |
Relocation of a business or organization to another premises or office |
|
Industrial espionage |
||
|
Lost archive |
||
|
Mergers & Acquisitions |
Merger/acquisition of enterprises/organizations |
|
|
Negative Publicity |
Negative information about the company in the press |
|
|
Transition from a manual to an automated information system or from one automated system to another |
||
|
"Attack" of criminal, commercial or government structures |
||
|
Human |
Labor conflict (strike, lockout, etc.) |
|
|
Loss of Workforce |
Organized departure of employees or their loss as a result, for example, of an accident |
|
|
Inability to recruit employees |
||
|
Succession Planning |
Lack of succession planning |
|
|
The Human Factor |
Human factor, terrorism in any form and using any weapon |
|
|
Unauthorized Access |
Unauthorized access |
|
|
White Collar Crime |
White collar crimes |
|
|
Workplace Violence |
Violent conflicts in the workplace |
|
|
Technogenic |
Rolling blackout |
|
|
Computer Failure |
Computer failures |
|
|
Computer Harking |
Hacker attacks |
|
|
Computer Viruses |
Computer viruses |
|
|
Environmental Hazards |
Accidents of life support systems (break of sewerage, hot and cold water pipelines, failure of air ducts, etc.) |
|
|
Multi-Tenant Sites |
Problems caused by housing several companies in one building |
|
|
Power outage |
||
|
Sick Building Syndrome |
A syndrome caused by the presence of harmful impurities in the materials from which a building is constructed |
|
|
Transportation Disruptions |
Public transport disruptions |
|
|
Natural |
blizzard |
|
|
Earthquake |
||
|
Electrical Storms |
Electromagnetic storms |
|
|
Natural-technogenic |
Winter weather |
|
|
Biological Hazards |
Epidemics |
|
|
Flood |
||
|
Artificial and natural objects landing |
Falling of artificial (for example, airplanes) and natural (for example, meteorites) objects from the sky |
It should be noted that awareness of the need to take care of information security and the associated development of plans to ensure the continuity of the functioning of information systems is already a big step for Russian enterprises towards ensuring business sustainability.
It does not consider a large layer of business risks associated with changes in the exchange rate of the national currency, government regulation that harms commercial activity, or the political system. These risks deserve special consideration because they are mitigated using methods that differ significantly from those described in this article.
Plan for ensuring uninterrupted operations of the organization in case of emergency situations: questions and answers
After a disaster, you need to start rebuilding your business. At the same time, some organizations are in a more advantageous position: they have a “Plan for ensuring uninterrupted operations of the organization” (hereinafter referred to as the plan).
Why do you need a plan?
National and international news headlines constantly include reports of a wide variety of disasters. Many disasters come unexpectedly, and in this case there is no time to plan and organize work: you need to fight for survival. Because the damage caused by disasters cannot be prevented, organizations need to protect themselves with a plan that will ensure a successful recovery. The recovery problem is further aggravated by the complexity of distributed computing environments, heterogeneity of hardware, software and communication protocols.
Nowadays, almost all companies rely heavily on computer technology or automated systems. The failure of these systems, even for a few hours, can lead to significant financial losses and even threaten the existence of the organization.
As more and more business-critical processes migrate to distributed computing systems (such as client-server), companies are beginning to worry about how to protect these systems in the event of a disaster. When applications are moved from the data center, where security and environmental controls are tightly controlled, to the operational workplace, the potential for business interruption increases significantly. For a computer center, fires, water and sewerage breaks, telephone and power outages are controllable and very rare, but with the distribution of applications over local or global networks, the likelihood that an emergency will occur somewhere increases greatly.
Organizations must consider measures to restore those areas of their activities that are critical to their business. At the same time, not only the information system must be restored. It is necessary to provide for the replacement of equipment of local telephone exchanges, the restoration of help desks and remote services, the provision of places for employees to work, and the salvage of property that is suitable for use (the list is not exhaustive). If such components cannot be restored in a timely manner, managing the organization becomes almost impossible.
Most companies can ensure continued operations after a disaster interruption by taking a number of specific steps.
What is a plan and why is it so important?
An organization's business continuity plan is a detailed list of activities that must be completed before, during, and after a disaster. This plan is documented and tested to ensure it works under changing conditions.
What are the benefits of having a plan?
The plan serves as a guide during a crisis and ensures that no important aspect is missed. A professionally written plan guides the actions of even inexperienced employees.
Having a detailed, regularly tested plan will help protect any organization from lawsuits due to negligence. The very existence of the plan is proof that the company's management has not neglected to prepare for possible disasters.
The main benefits of developing a detailed business continuity plan are:
- Minimizing potential financial losses.
- Reduced legal liability.
- Reducing disruption time.
- Ensuring the stability of the organization's activities.
- Organized restoration of activity.
- Minimizing the amount of insurance premiums.
- Reducing the workload on leading employees.
- Better security of property.
- Ensuring the safety of personnel and customers.
- Compliance with laws and regulations.
What are the consequences of not having a plan?
An often cited study conducted by the University of Texas found the following statistics:
- 85% of organizations rely heavily or completely on computing systems.
- On average, on the 6th day of a business interruption, a company loses 25% of daily income, and on the 25th day - 40%.
- After a business interruption, there is a rapid increase in financial losses and deterioration in functioning.
- Two weeks after a computer system shutdown, 75% of companies experience critical or complete loss of functionality.
- 43% of companies that experience disaster and do not have a business continuity plan do not resume operations, and two years later only 10% of companies are still operating.
This study found that organizations that created contingency plans had significantly lower incremental costs and revenue losses.
It is estimated that the loss of income for this group of organizations would have been 2.5 times higher if they had not implemented appropriate plans in the event of an emergency.
Who is responsible for developing the plan?
Ultimately, the development of the plan is the responsibility of the company's management, which must exercise control over the company's assets, which includes monitoring the company's information systems and ensuring their continued functioning.
Problems associated with restoring the functioning of the information system should be a concern of the entire company, and not just the management of the department responsible for the IT infrastructure. Managers of all departments that rely on the services provided by the IT Technology Department should develop emergency procedures specific to their own functions and participate in the development of the business recovery plan. Each function must put its part of the plan into action as part of the overall recovery effort. The plan should even reflect the implementation of such supporting functions as the maintenance of buildings and equipment. The effectiveness of these functions may not directly affect the operation of the IT infrastructure, but the restoration of the operation of technical equipment will partially depend on it.
What is required to develop a plan?
An important point in the plan development process is the participation of the company's senior management. Without his support, it is nearly impossible to get functional units to provide the resources needed to develop the plan.
User participation is also essential. If users are not involved in the plan development process, it is unlikely that the plan will be truly useful. Their participation will help determine some important factors:
- The likely consequences of each disaster for the organization's activities;
- The likely duration of each possible disaster;
- Resources needed to minimize possible consequences;
- "Human resources.
Maintaining a Business Continuity Plan requires ongoing investment of time and financial resources.
Not updating your plan is just as bad as not having one at all!!!
What are the stages in developing a plan?
The development of a business continuity plan must be organized as a project to manage tasks, deadlines and deliverables. The main stages of a typical project are:
- Organization of project implementation;
- Risk assessment, reduction of undesirable consequences from the occurrence of risk-related events, analysis of business consequences;
- Development of a strategy for business recovery;
- Documenting the plan;
- Education;
- Simulated disaster.
Organization of project implementation
Organizing project execution includes project administration, defining assumptions, conducting meetings, and developing policies.
Risk assessment
A risk assessment identifies the types of disasters that are likely to occur in any given location. The physical infrastructure of the building and its surroundings is examined. For each type of disaster, an estimate of the possible duration is made and a relative value is assigned corresponding to the probability of their occurrence. A scale is used, for example from 0 to 3; where 0 means an unlikely event, and 3 means a very likely event. This will highlight areas where further research should be undertaken to reduce the impact of risk events.
Analysis of the consequences for the organization's activities
After the risk assessment, an analysis of the consequences of the disaster for the organization's activities is carried out, during which losses due to the inability to continue normal activities are determined. They may be obvious or more abstract in nature, in which management will have to make a guesstimate estimate of losses. In any case, the goal is not to get a definitive answer, but to identify the factors that are critical to the company's continued operations. At this stage, the scope of the business continuity plan is determined. Excessive precautions will require unnecessary funds, and insufficient ones will not provide adequate safety.
Developing a Business Continuity Strategy
Once the requirements have been determined, decisions can be made on how to ensure business recovery. There are many technical solutions available, including:
- Use of a "hot" standby room. The supplier provides the company with a prepared workspace containing equipment, telecommunications, technical support personnel, etc., usually on an annual contract. Customers receive access to equipment on a first-come, first-served basis.
- Use of a "cold" reserve room. The company organizes work in empty or rented premises that are prepared for use. Immediately after a disaster, equipment (possibly purchased from suppliers), software, and support services are deployed on premises.
- Use of internal reserves. To provide services in emergency situations, company equipment located in another location is used.
- Concluding a mutual support agreement. An agreement is entered into with another company to share resources after a disaster. This assumes that backup equipment always has the required performance and that you are satisfied with the degree of information protection during teamwork.
In some cases, a combination of these options may be used. Large multinational companies most often use the internal redundancy method for local computer networks. Since the number of spare rooms available is limited, it may be that in the event of an emergency there will be no work space available to use. A regional disaster could result in all of the reserve space being occupied, leaving the company with nowhere to resume operations.
A well-prepared plan provides a company with step-by-step instructions appropriate to the type and severity of the disaster. It specifies the functional groups of company specialists trained to implement the plan. Having a well-developed plan ensures that in a stressful situation following an emergency, critical factors are not overlooked.
Documentation
The plan can be documented in a variety of ways. Most companies still use traditional word processors; others use commercial software. Whatever method is used, it is important to ensure that change control procedures are strictly followed to keep the plan relevant to the actual situation at hand.
Education
The "Recovery Team" training is aimed at ensuring that each employee knows their roles and responsibilities in the event of emergency situations.
Simulated disaster
Most companies test the plan at least once every six months. By simulating disasters, you can test the plan, find its weak points and work out the interaction of participants. Discovering deficiencies usually leads to adjustments to the plan. The plan should be tested and adjusted regularly. Few business continuity plans are carried out as originally envisaged. Since amendments to the plan must be made regularly, the procedure for adjusting the plan should be as simplified as possible.
What else should be considered?
When developing a business continuity plan, the following should be considered:
- If a plan is not currently in place, senior management should be made aware of the potential dangers associated with not having a prepared and tested plan;
- If there is a plan, it is necessary to ensure its regular testing - to carry out a cyclic replacement of specialists participating in the tests. It is advisable that the maximum number of employees take part in this process;
- Management must ensure that business continuity planning is one of its objectives;
- When choosing alternative work spaces, care must be taken to ensure that they can be used when necessary;
- Don't take existing reservation systems and procedures at face value: conduct a full review of your reservation and make any necessary changes. Test recovery procedures;
- When prioritizing applications, poll executives for their views;
- Take into account in the plan all the little things that could interfere with the process of restoring activity;
- Once your plan is in place, develop a mechanism to ensure it is updated regularly.
What specific functional areas should be included in the plan?
The plan must contain procedures for performing the following functions:
- Putting emergency procedures in place.
- Notifying employees, suppliers and customers.
- Formation of recovery group(s).
- Assessing the consequences of a disaster.
- Making a decision to implement a business recovery plan.
- Implementation of business recovery procedures.
- Moving to alternative work premises(s).
- Restoring the functionality of critical applications.
- Restoration of the main work space.
In addition, the plan should contain documents that can be used by personnel unfamiliar with the specific functions being restored. These documents must include the following information:
- Telephone switching diagrams;
- Procedures for emergency power outage;
- Organizational structure of the Recovery Center;
- Requirements for equipment and supplies of the Recovery Center;
- Recovery Center configuration;
- List of critical applications;
- List of restored equipment;
- Risk Assessment Summary.
To implement the Business Continuity Plan, it usually provides for the creation of certain groups within the organization (Table 3).
Table 3. List of groups for implementation of the “Plan”
|
Group name |
|
|---|---|
|
Initial Response Team |
Determines the extent of damage |
|
Recovery group |
Serves as a command center during the recovery process |
|
Public Relations Group |
Prepares press releases and liaises with the media |
|
Facilities Management Group |
Equips a new premises and begins reconstruction of the damaged work premises |
|
HR group |
Solves problems related to business trips, relocations, employee injuries, etc. |
|
Computing Systems Group |
Restores production infrastructure |
|
Functional activity group |
Coordinates the resumption of work of all functional units involved in the business |
|
Group of information transmission systems |
Restores the communication network for data transmission |
|
Accounting group |
Coordinates the rescue, recovery of damaged records and their storage off-site |
|
Administrative Support Team |
Provides support for the work of the Recovery Team |
Ways to make a plan
There are three main ways to develop a plan:
- On your own.
- Using commercial business continuity planning software (demo versions of such programs can be viewed or downloaded from the website of the independent American disaster recovery journal, Disaster Recovery Journal (see Appendix I).
- Engaging an external consultant to provide assistance or directly develop the plan.
The methods differ in cost, but in all cases the allocation of personnel is required to conduct research and implement the plan.
Developing in-house requires expertise in creating a business continuity plan. This qualification can only be acquired through extensive training and experience. Most organizations do not have this capability.
What can you do yourself?
The following (non-exhaustive) list may give company management some insight into how to prepare for the recovery of their distributed computing systems:
- Identify potential threats and prioritize them according to their likelihood of occurrence.
- Assess the impact of each potential disaster and determine what could be damaged.
- Assess the time required for recovery and the potential damage from business interruption.
- Identify critical resources.
- Take an inventory of your property.
- Take care of the built-in fault tolerance function (mirror disks, RAID, UPS, etc.).
- Protect your applications and data (virus protection, off-site backups, etc.).
- Maintain the functionality of data transmission systems.
- Create alternative workspaces and develop a plan to obtain the required resources.
- Prepare a formal plan and test and update it regularly.
Development methodology and approximate content of the organization’s business continuity plan
Disaster Continuity Planning refers to the identification and protection of critical business processes and resources necessary to maintain the organization's operations at the desired level, and the development of procedures that will ensure the organization's survival if its normal operations are disrupted.
Development methodology
An organization's disaster continuity plan is not only a technical plan - it primarily involves organizational measures. Therefore, the plan should be based on information about the structure and functions of the organization, the funds necessary to maintain its activities, the magnitude of the damage from the inability to function normally, the people who will take control in a crisis situation, and the procedures they will use. To structure the plan development process, it is necessary to use an appropriate methodology to ensure that all continuity factors are taken into account.
The methodology (as follows from the figure) consists of three stages and ten stages, which together make up the life cycle of the project to develop a plan for ensuring the continuity of the organization's activities (the content of the work at the stages is described in detail in the next chapter).
Planning of the organization's activities is based on the following main factors: quality of services, operational efficiency and the possibility of development of the organization. In many ways, it is provided by the technology adopted in the organization. Therefore, it is important that when identifying critical areas of an organization's activities, their dependence on technology components is taken into account.
Previously, contingency plans only considered computer-related disasters. This is a very narrow approach. To ensure smooth operations, it is necessary to take into account all interrelated external and internal functions, including manual methods of accounting and information processing.
The most important factors for planning success are taking into account all the details and developing each small element of the plan step by step. It must be determined what scale of events the plan is designed for. If the organization is located in an area where regional disasters may occur, the plan must include the possibility of interruption of power, water, and other utilities. Otherwise, it is enough to consider the possibility of disasters only at the scale of the building and rely on the help of suppliers, authorities and city structures.
The “breadth” of the plan must also be established. It depends on many factors, in particular, on the structure of the organization, allowable costs, the number of existing buildings, etc.
The Disaster Continuity Planning methodology is based on a pragmatic approach to maintaining critical processes. Protecting all aspects of an organization from harm in the event of a disaster is either unrealistic or prohibitively expensive.
The objectives of the project to develop a plan to ensure continuity and recovery of the organization's operations in the event of disasters are:
- Create a business process assessment methodology that will ensure the plan is developed using a well-structured and comprehensive methodology.
- Develop a pragmatic, cost-effective and workable plan that will ensure continuity of critical processes in the event of a major disruption to the organization.
An effective business continuity plan is a relatively inexpensive form of insurance for companies against the consequences of possible disasters, and the cost of it should be considered as part of the necessary costs of maintaining the normal functioning of the organization.
Approximate content of the plan
An indispensable condition for the rapid and successful restoration of an organization's activities after a disaster is the preliminary development and regular updating of a permanent business continuity plan. Depending on the specifics of the company and the policies adopted in it, such an action plan can take different forms and names. It may consist of several sections reflecting different areas of work: emergency preparedness plan, emergency action plan, information backup and recovery plan, business recovery plan, etc. The plan may also be detailed by category and duration of emergency.
The plan includes the following main sections:
- Main provisions of the plan.
- Emergency assessment:
- identifying company vulnerabilities;
- classification of possible hazardous events and assessment of the likelihood of their occurrence;
- emergency scenarios;
- potential sources of negative consequences of each emergency situation and assessment of the amount of damage;
- a set of criteria based on which an emergency is declared.
- Company activities in emergency situations:
- initial response to an emergency (assessment of a dangerous event, declaration of an emergency, notification of the necessary circle of people, implementation of an emergency plan);
- measures to ensure the uninterrupted operation of the company in an emergency and the restoration of its normal functioning.
- Maintaining emergency preparedness:
- monitoring the correctness and adjusting the content of the plan;
- compiling a list of addresses and procedures for distributing the plan;
- development of a program for advanced training and familiarization of personnel with the actions necessary to restore the company’s activities after a disaster;
- preparing for hazardous events, ensuring safety and preventing disasters;
- regularly conducting partial and comprehensive checks (such as fire drills) of the company’s readiness to act in an emergency and ability to restore normal operations;
- regularly creating backup copies of data, documentation, forms of input and output documents and main software, storing them in a safe place.
- Information Support:
- priority functions performed by the company;
- lists of internal and external resources - hardware, software, communications, documents, office equipment and personnel;
- accounting information on technical, software and other support necessary to restore the organization’s activities in the event of an emergency;
- a list of persons who must be notified of an emergency situation, indicating addresses and telephone numbers;
- auxiliary information - plans and diagrams, transportation routes, addresses, etc.;
- description of detailed step-by-step procedures to ensure strict implementation of all provided measures;
- roles and responsibilities of employees in the event of unforeseen circumstances;
- the timing of the restoration of activities depending on the type of emergency situation that has arisen;
- cost estimates, sources of financing.
- Technical support:
- creation and maintenance of a base of technical means to ensure uninterrupted operation of the company in an emergency;
- creation and maintenance of reserve production premises in proper condition.
- Organizational support, composition and functions of the following groups to ensure uninterrupted operations in the event of a disaster:
- emergency assessment teams;
- crisis management teams;
- emergency teams;
- recovery groups;
- work support groups in the reserve production facility;
- administrative support groups.
Even a simple listing of the elements of the plan indicates the seriousness of the problem and the amount of work involved in its preparation.
Stages of an organization's business continuity planning methodology in the event of a disaster
Organizations involved in assessing the qualifications of specialists in certain fields of activity usually formulate a general body of knowledge of specialists in this profession. This body of knowledge is abstract in nature, it is stable and independent of the technology used, which facilitates communication between specialists in this field and establishes uniform requirements for their qualifications.
Mastering a general body of knowledge is necessary, but not the only proof of professional abilities. To successfully pass the qualifying exams conducted on its basis, it is necessary to conduct professional activities and have certain skills in this field.
The qualification must correspond to the content of the general body of knowledge.
The material in this chapter is based on the work of the Disaster Recovery Institute International (DRI International). The purpose of the institute’s activities is the accumulation and dissemination of practical experience, the formulation of a base of publicly available knowledge of specialists and organizations developing action plans to ensure the uninterrupted functioning of organizations and the restoration of their activities after a disaster.
The body of knowledge consists of 9 subject areas corresponding to the stages of the organization's business continuity planning methodology in the event of a disaster.
Each area contains the following information:
- description of the subject area,
- specialist functions,
- qualifications that a specialist must have to perform his functions in a given field.
Guidance on creating a business continuity and recovery plan for an organization after a disaster
Description of the subject area:
The management includes the rationale for the need to complete the project, determines the organizational structure of project management and the structure of the project itself.
Specialist functions:
- Formation of a project implementation strategy, i.e. formation of requirements, determination of the scope and goals of the project, legal justification, analysis of examples of successful implementation of similar projects (best practice);
- Development of the project budget;
- Determining the organizational structure of project management and the structure of the project itself;
- Project progress management;
- Development of job descriptions;
- Development of recommendations for management and employees in the following areas of work:
- cooperation with other organizations;
- conducting negotiations;
- searching for compromises;
- acting as a mediator;
- approval of documents.
The specialist must be able to:
- Formulate the problem.
- Convince of the need for an action plan to ensure the smooth functioning of the organization:
- justify the need for the project;
- formulate the goal of the project;
- demonstrate the benefits of having a plan;
- seek support from senior management;
- ensure employee involvement in working on the plan.
- Formulate the functions of senior management.
- Understand the reporting structure and responsibilities of various levels of management.
- Create a committee to guide planning:
- formulate its functions,
- determine the structure
- ensure management of its activities and development,
- determine its composition.
- Develop requirements for financial and human resources.
- Establish the composition and responsibilities of the planning group(s).
- Develop and coordinate action plans.
- Develop requirements for project management and documentation.
Risk assessment and risk management
Description of the subject area:
Identification of events that may have a negative impact on the organization’s activities, assessment of possible damage and identification of measures necessary to prevent or minimize losses.
Specialist functions:
- Identification of potential risk factors for the organization, their likelihood and consequences;
- Determining the need for external expertise;
- Identification of the organization’s vulnerabilities;
- Identification of alternative ways to reduce risk;
- Identification of trustworthy organizations providing information services;
- Interaction with management to determine acceptable risk levels;
- Drawing up documentation and presenting the results obtained.
The specialist must be able to:
- Predict the consequences of random dangerous events;
- Understand the following sources of potential damage:
- natural,
- artificial,
- random,
- deliberate,
- internal,
- external.
- Assess the likelihood of damage to the organization as a result of various unfavorable factors;
- Determine control actions and precautions to prevent or minimize losses:
- know the infrastructure and design of buildings;
- identify vulnerabilities;
- detect adverse factors, report them and reduce their impact;
- carry out personnel activities;
- ensure security and access control to the protected area;
- formulate a backup archiving policy;
- ensure the safety and protection of information, including on a computer network, both hardware and software;
- manage preventative maintenance and schedule equipment installations;
- ensure duplication and redundancy of power supply systems,
- cooperate with external organizations.
- Use risk analysis tools to:
- determine qualitative and quantitative risk assessment;
- compare the benefits of risk reduction measures and their costs;
- Use a variety of methods and means of collecting information:
- forms and questionnaires;
- surveys;
- meetings;
- viewing documentation;
- examinations.
- Determine the likelihood of hazardous events using various sources of information and assessing the reliability of the relevant data;
- Assess the effectiveness of control actions and precautionary measures, i.e.:
- determine the cost-benefit ratio;
- analyze the quality of procedures for implementing activities and management;
- carry out tests;
- carry out an audit of functions and responsibilities.
Analysis of the consequences of disasters for the organization's activities
Description of the subject area:
Determination of the consequences of disruption of normal functioning for the organization, quantitative and qualitative assessment of such consequences.
Specialist functions:
- Identification and specification of functions (business processes) of the organization;
- Search for knowledgeable and trustworthy specialists in the organization’s field of activity;
- Determining the criteria by which functions are classified as critical;
- Submitting criteria to management for approval;
- Coordination of work to analyze the consequences of a disaster for the organization’s activities;
- Identification of interconnections between functions;
- Determining the limitations of the functional restoration process:
- prioritization of functions;
- setting deadlines for restoration of functions;
- loss assessment.
- Identification of information needs;
- Determining resource needs;
- Determining the report form;
- Preparation and presentation of analysis results in the form of a report.
The specialist must be able to:
- Determine the possible consequences of disruption of the normal functioning of the organization:
- loss of property (material, informational);
- interruptions in the provision of services and activities of the organization;
- violations of legal requirements and regulatory documents.
- Understand the implications for the organization regarding:
- financial situation;
- interaction with customers and suppliers;
- image in the eyes of the public;
- legal obligations;
- compliance with the requirements and conditions of regulatory documents;
- violations of environmental protection requirements;
- operational activities;
- personnel;
- other resources.
- Understand quantitative and qualitative impact assessment methods;
- Determine the criticality of functions;
- Conduct:
- quantitative assessment:
- loss of property,
- lost income,
- fines,
- losses due to disruption of cash flow,
- accounts receivable,
- accounts payable,
- loss of human resources,
- additional expenses,
- qualitative assessment:
- loss of human resources,
- losses due to legal obligations,
- social losses,
- moral damage,
- loss of trust.
- quantitative assessment:
- Identify functions that are critical to the organization and their relationships.
- Set priority functions.
- Determine minimum resource requirements:
- internal,
- external,
- monetary,
- additional.
- Determine the timing of resource recovery.
Developing strategies for restoring the organization's activities
Description of the subject area:
Identification of alternative organizational recovery strategies that can ensure the preservation of critical functions and provision of recommendations for their selection.
Specialist functions:
- Identification of available alternatives, determination of their advantages and disadvantages, cost estimation.
- Search for effective strategies for restoring organizational functions.
- Integration of strategies.
- Formulation of requirements for storing data and documentation in external storage and selection of backup premises.
- Ensuring support of strategies by structural divisions of the organization.
- Presenting the strategy to management and ensuring their buy-in.
The specialist must be able to:
- Determine the requirements for the organization’s recovery strategy according to the following criteria:
- recovery time;
- type of strategy;
- objects to be restored;
- necessary personnel;
- required means of communication.
- Select an appropriate recovery strategy from the following components:
- take no action;
- defer action;
- use manual procedures;
- enter into a mutual agreement with another organization;
- use reserve workspace;
- use the services of an external computer center;
- enter into a consortium with other organizations;
- organize distributed data processing;
- use alternative means of communication.
- Select backup workroom(s) and external storage for data and documents:
- establish selection criteria;
- determine the necessary means of communication;
- formulate the terms of agreements;
- develop comparison methods;
- purchase premises and technical equipment;
- formulate the terms of contracts.
- Conduct cost-benefit analysis.
Emergency response
Description of the subject area:
Development and implementation of procedures for responding to an emergency and preventing its development.
Specialist functions:
- Determine whether the organization has emergency response procedures.
- Develop emergency response procedures in the event of their absence.
- Integrating post-disaster recovery procedures with emergency response procedures.
- Determination of requirements for management and control during emergency response.
- Develop command and control procedures that clearly define the roles, authorities, and communication processes needed to respond to an emergency.
The specialist must be able to:
- Develop emergency response procedures, including:
- ensure emergency preparedness:
- develop response procedures detailed by disaster type, for example:
- natural disaster,
- accident,
- deliberate action
- determine the powers of management,
- determine means to ensure uninterrupted management,
- determine the functions of dedicated personnel,
- develop response procedures detailed by disaster type, for example:
- regulate actions in emergency situations, which consist of:
- emergency notification,
- evacuation,
- providing medical care,
- activities for handling hazardous materials,
- combating disasters (fire, flooding, etc.)
- provide:
- safety of equipment and premises,
- reduction of damage caused,
- testing,
- define job responsibilities,
- prepare reports:
- internal:
- within a separate division,
- within the organization as a whole,
- external:
- for the public,
- for suppliers.
- internal:
- ensure emergency preparedness:
- Identify means and methods of emergency management and control, including:
- development of a project for an emergency center and its equipment,
- determination of powers for management and decision-making in an emergency situation,
- determination of the necessary means of communication (radio communications, courier communications and cellular telephone communications),
- development of registration methods and documentation.
- Develop emergency center management and control procedures covering:
- opening of the center,
- ensuring the security of the center,
- drawing up a work schedule for the center’s working groups,
- management of the center and control of its activities,
- closure of the center.
Development and implementation of a plan to ensure the smooth functioning of the organization
Description of the subject area:
Development of a concept, drawing up and implementation of an action plan to ensure the smooth functioning of the organization.
Specialist functions:
- Planning activities to develop and implement the plan.
- Organization of work on the plan.
- Management of work on the plan.
- Monitoring and adjusting the progress of work on the plan.
- Providing work with specialists.
- Implementation of the plan.
- Test plan.
- Maintaining a plan.
The specialist must be able to:
- Determine the requirements for the Plan:
- apply planning tools,
- use:
- job descriptions,
- action plans,
- checklists,
- matrices,
- shapes,
- other supporting documentation.
- Determine requirements for management and operational management of business recovery:
- recovery group concept:
- description,
- organization,
- Responsibilities of recovery team members:
- recovery coordinator
- coordinators of specialized groups,
- responsibilities of support personnel,
- requirements for a backup center to operate in an emergency.
- recovery group concept:
- Identify and describe the form and structure of the main elements of the plan.
- Prepare a general introduction to the main provisions of the plan:
- general information:
- preface,
- content,
- goals,
- assumptions
- general information about responsibilities,
- tests,
- accompaniment,
- putting the plan into effect:
- notification:
- primary,
- secondary,
- disaster declaration procedures,
- mobilization procedures,
- damage assessment concept:
- original,
- detailed,
- notification:
- organization of a recovery group:
- description,
- compound,
- manager's responsibilities,
- policy statement,
- emergency center.
- general information:
- determine the functions of supporting recovery units:
- provision of human resources,
- security,
- insurance and risk management,
- purchase of equipment and materials,
- transportation,
- taking into account legal aspects,
- regulate the appointment of a public and media relations coordinator, defining the required qualifications and job responsibilities, including:
- communication with government authorities,
- investor relations,
- prepare sections concerning:
- recovery groups:
- Group members,
- responsibilities of members
- necessary resources,
- recovery groups:
- checklists,
- technical procedures.
- Develop a plan for the organization’s production activities:
- draw up plans for the operational department, including:
- core business functions,
- activities to put the plan into effect,
- actions to restore the work premises damaged by the disaster and return it to its original condition,
- ensuring the safety and recovery of information,
- end user needs for computing equipment,
- define the elements of a program for creating vital archives,
- prepare sections of the plan related to actions:
- recovery groups:
- Group members,
- responsibilities,
- necessary resources,
- recovery groups:
- develop action plans:
- general plans of individual departments and individual plans of employees,
- checklists,
- technical procedures.
- draw up plans for the operational department, including:
- Develop a plan for restoring information infrastructure:
- starting the operation of the backup center:
- center management,
- administrative management,
- logistics,
- installation of new equipment,
- Maintenance,
- support for solving applied problems,
- networking,
- data transmission over the network,
- operational activities,
- ensuring transportation and communication between work premises,
- data preparation,
- operational production management,
- establishing communication with end users,
- meeting end user requirements,
- defining the elements of a program for creating vital archives,
- action plans:
- general plans of individual departments and individual plans of employees,
- checklists,
- technical procedures.
- recovery group actions:
- Group members,
- responsibilities,
- necessary resources.
- starting the operation of the backup center:
- Develop plans to ensure uninterrupted operation of communication systems.
- Develop plans to ensure uninterrupted operation of end-user application systems.
- Establish procedures for disseminating, monitoring and adjusting the plan.
- Implementation of the plan:
- development of an employee training program:
- standard recommendations,
- roles and responsibilities of employees,
- procedures,
- familiarization with the plan and practical training in the activities provided for in it,
- producing a presentation,
- performing the necessary work:
- purchase of additional equipment,
- conclusion of contracts,
- preparing backup copies and ensuring storage of data and documents in external storage,
- development of test plans and schedules, as well as reporting procedures,
- developing procedures for maintaining and updating the plan and related reporting.
- development of an employee training program:
Prepare a section on administrative management:
Introductory programs and practical training for the organization’s personnel
Description of the subject area:
Implementation of a program to familiarize personnel with the problem of ensuring the uninterrupted functioning of the organization and improving the qualifications of personnel in terms of introducing, implementing and maintaining a plan to ensure the uninterrupted functioning of the organization.
Specialist functions:
- Determining the goals and elements of the training program.
- Setting functional training requirements.
- Development of teaching methods.
- Development of a program to familiarize staff with the problem of ensuring the smooth functioning of the organization.
- Acquisition and development of teaching aids.
- Identifying and pursuing learning opportunities outside the organization.
- Determining materials and ways to familiarize personnel with the problem of ensuring the smooth functioning of the organization.
The specialist must be able to:
- Define learning goals.
- Develop training programs of various types:
- using computer technology,
- in the classroom,
- based on tests.
- Develop introductory programs:
- for guidance,
- for group members,
- for a newly hired employee.
- Identify other learning opportunities:
- professional conferences and seminars on business continuity planning,
- participation in user groups,
- publications.
Testing the plan and conducting exercises to implement the plan
Description of the subject area:
Pre-planning exercises to implement the plan, conducting exercises to implement and test the plan, evaluating and documenting the results of tests and exercises.
Specialist functions:
- Advance test planning.
- Coordination of testing.
- Test plan evaluation.
- Conducting exercises to implement the plan.
- Drawing up documentation of the results.
- Evaluation of results.
- Adjustment of the plan.
- Informing management about test results and their evaluation.
The specialist must be able to:
- Develop a testing program.
- Determine testing requirements:
- goals and criteria for assessing test success,
- types of tests (advantages and disadvantages):
- simulation modeling and comprehensive testing,
- partial,
- functional,
- with prior notice,
- without prior notice,
- definition and description of test content,
- development and expansion of testing,
- test frequency,
- ensuring logistics, transportation and advance planning.
- Develop realistic test scenarios:
- develop test scenarios that are close to the situation of possible emergency incidents and provide for the resolution of all emerging problems,
- provide team members with hands-on training on how to perform new functions involving decisions that go beyond their normal job descriptions,
- conduct exercises on opening a backup center for work in an emergency, creating communications facilities, conducting registration and drawing up documentation:
- recovery:
- damage assessment,
- restoration of work premises,
- equipment restoration,
- creation of working conditions,
- rescue and return to its original state (use of specialist services),
- insurance.
- recovery:
- Establish criteria for evaluating test results:
- observation,
- registration,
- grade:
- comparison of expected and actual results,
- development of recommendations for adjusting the plan.
Maintaining and updating the plan
Description of the subject area:
Developing procedures that keep the plan up to date to ensure the smooth functioning of the organization.
Specialist functions:
- Participation in strategic planning meetings.
- Coordination of work on maintaining the plan.
The specialist must be able to:
- Understand the strategic directions of activity.
- Set criteria for adjusting the plan:
- periodic adjustments,
- when significant changes occur,
- according to test results.
- Maintain a plan:
- own tools,
- control the actions of employees,
- make adjustments,
- carry out audit and control.
- Maintain reports on the status of the plan.
- Establish procedures for communicating the plan to all employees and monitoring their implementation.
Examples of business continuity plans for information processing systems
Currently, the activities of all companies without exception are carried out using information technology.
Restoring a local area network after a disaster
In order for the restoration of the functioning of the LAN to take place in an orderly manner, quickly and without any unforeseen delays, it is necessary to have a clear plan in case of emergency circumstances. Each plan must have at least the following sections:
Title page. The official name of the plan, account number, dates of preparation, amendments and approvals, names of managers and executors.
Target. A brief description of the purpose of drawing up the plan, the LAN for which it is intended. The "highlights" of the plan allow anyone who picks up the plan to quickly get an idea of it.
General strategies. This section provides a general description of the plan and also:
- Procedures for initially assessing the situation and putting the plan into action.
- A set of criteria based on which a disaster is declared.
- List of responsibilities of employees when restoring a LAN.
- A general list of actions performed by the LAN recovery coordinator and other key employees.
- A general list of restoration work that ensures either the organization of LAN operation in a backup center or the restoration of its functioning in a production facility that has suffered damage.
- Summary assessment of damage and information about the necessary work to repair LAN equipment.
- Time required to restore functionality.
Accounting information. It may contain different types of credentials. For example, the standard server configuration, the standard workstation configuration, directory structure, other configuration data, a list of identifiers associated with the server, copies of system files for each workstation, and any other types of credentials that will help perform LAN recovery.
Composition of a disaster recovery team. A list of all individuals who will be involved in LAN restoration, including name, home address, home phone, work phone, pager and cell phone numbers, if available. The same list should include the names, addresses and telephone numbers of the supplying companies. You can also include the manager's addresses and phone numbers and other "useful" numbers.
Advance arrangements. A list of activities that need to be carried out long before a disaster occurs in order to reduce the risk of its occurrence and possible consequences. One of these important activities is the creation of backup copies. The plan should include when backups are taken, where they are sent, when they are sent, what the label on the backup media should look like, and anything else that might be needed to actually create the backups. Standardization of labels and media will make it easier for those who will store copies and those who will have to reconstruct information from them. The information on the labels should ensure that the media can be easily transported from your LAN premises to your off-site storage location and back and that it can be easily used.
LAN recovery procedures. This section specifies the required contingency actions and measures to restore the functioning of the LAN in various situations. Recommendations are given for the correct use of plan materials. Space should be left to mark the completion of each step, indicating the name of the person responsible, the date and possibly the time of completion. This ensures that no step is missed.
Maintaining a plan. This section must establish the procedures for maintaining the plan, particularly the frequency of updating the relevant plan documentation and the person responsible for this action. In addition, recommendations are given on the preparation of planning documents, their distribution and training in methods of drawing up and maintaining a plan. If the operating procedures are determined by the general procedures established in the company, reference may be made to them.
Test plan. This section describes what should be tested when testing the feasibility of a plan, who should conduct the tests, when the tests should be performed, and what the results are. The test plan can be general or consist of separate parts. Some sections of this plan may be sections of other general plans.
Applications.- Contains various forms, agreements, etc.
Even in this schematic form, the above version of the plan will be very useful for most LANs and does not require large development costs, because it can be compiled using a regular text editor.
When creating a LAN recovery plan after a disaster, you should adhere to the well-known principle of “Keep It Simple Stupid.” True, if you have no recovery plan at all, simplicity, of course, is taken to the limit, but as for wisdom...
Plan for creating backup copies and restoring information on the LAN
When it comes to backing up network information, some organizations take a risk. Attitudes tend to change when a disaster strikes the LAN.
"Time is money". The validity of this saying becomes especially obvious when, due to a LAN failure, the normal activities of the entire organization are disrupted. According to Jeff Konz, systems administrator at Itron Corp. (USA), which produces laptop computers, his company loses approximately $25,000 per hour if the LAN is inoperable.
Backup policies may vary. It is advisable to create full backup copies of the source code of programs and critical applications once a week, and incremental backups every night. To check the quality of tape backups, you need to regularly restore the copied information on another computer.
The performance of the information backup and recovery system should not lag behind the increase in the company's computing power.
Despite the fact that specific regulations for backup and recovery of information vary from company to company, having a clear plan for carrying out the corresponding work is absolutely necessary.
The plan indicates: time regulations for creating backup copies, storage locations, type of labels on the media, and everything that may be required during actual work related to data recovery. Standardization of labels and media will make it easier for those who will store copies and those who will have to reconstruct information from them. The information on the labels should ensure that the media can be easily transported from your LAN premises to your off-site storage location and back and that it can be easily used.
Determining priorities is critical when drawing up a plan. After analyzing costs, you should analyze system requirements and set priorities that take into account factors such as the volume and list of existing data that needs to be backed up. Based on the analysis and set priorities, backup system resources are allocated.
Implementing a backup plan should be a daily concern for the company.
Often the ineffectiveness of this plan is only revealed when a disaster occurs. To prevent this from happening, it is necessary to regularly carry out inspection procedures such as “fire drills”. Since these information recovery procedures are quite labor-intensive, it is recommended to use special software to test them.
Contingency planning for banking information processing systems
In banking information processing, contingency planning is necessary to minimize the damage that can be caused by unexpected and unwanted events affecting data processing. Such situations arise both as a result of disasters that are difficult to prevent and the likelihood of their occurrence is relatively low, and as a result of predictable and fairly frequent events, such as failures of technical equipment or electrical power. The goal of contingency planning is to minimize negative consequences, regardless of the magnitude of the adverse event. Our dependence on computing systems has grown to such an extent that a return to manual data processing, if possible at all, would result in an unacceptable waste of time and money.
The starting point in contingency planning is to establish the principles to be followed in creating such a plan. Successful implementation of the plan can yield enormous benefits. To prevent the disastrous consequences of any disaster, it is necessary:
- know the relationships between all elements of the information processing cycle;
- have a general understanding of the likelihood of each adverse event;
- take measures in advance to minimize the amount of losses;
- save backup copies of files;
- improve the operating conditions of the data processing system;
- regularly update documentation;
- ensure standardization of hardware and software;
- develop emergency procedures;
- take into account the requirements for system backup and recovery in the technical policy.
The plan should outline a step-by-step process for restarting operations smoothly and as quickly as possible.
The contingency plan must be linked to the emergency preparedness and prevention plan. These plans should be developed in conjunction with acceptable levels of risk and cost.
The main purpose of creating a contingency plan is to allocate responsibilities (who should do what, when and how) to keep the organization running.
The draft plan should be submitted to senior management for review and approval.
Role of Management
The plan requires significant input from the data processing departments. However, the planning process as a whole should begin and end at the senior management level.
Senior management is well aware of the vulnerabilities of today's computer-based banking technology and therefore recognizes the need for contingency plans. The main function of management is to support such planning and designate a unit that should deal with it.
The first step is to prepare a memorandum reflecting management's position. Such a memorandum might, for example, read: “Each operational and administrative unit is responsible for the computer systems for collecting and processing data on which the bank depends. Because these systems support the functioning of the bank, managers of operational units must understand that for them the non-stop operation of computer systems is of greater importance than for heads of departments responsible for data processing." Developing a plan requires time, patience, and the direct involvement of leaders at all levels. A steering committee should be formed from representatives from all areas of activity to make policy recommendations.
To directly draw up a contingency plan, you can create a special unit consisting of a leader and a small group of assistants. Once the plan has been developed, the team leader may be assigned as the contingency planning coordinator, reporting to data management.
Note that management involvement must be constant to prevent the plan from becoming obsolete and to keep it usable.
Making a contingency plan
A contingency plan cannot be developed by one person. To ensure success, the coordinator must have not only the support of management, but also a group of subordinates. These employees must have a certain set of knowledge in this area. It must be borne in mind that in the event of a disaster, restoring operability will require time and money, and one of the goals of the plan will be to minimize these costs.
The plan must include the following information:
- names, addresses and telephone numbers of key employees;
- goals and responsibilities of employees when restoring operations;
- lists of required external resources, including hardware, software, communications, data, documents, office equipment, documentation and personnel;
- auxiliary information - transportation routes, maps, addresses, etc.;
- procedures detailing how personnel mobilization and recovery efforts should be carried out;
- administrative activities to coordinate work related to restoration;
- procedures for continuous adjustment and testing of the plan;
- mailing list for the plan.
The plan must be detailed to such an extent as to simplify decision making as much as possible.
The plan should be updated quarterly to ensure the accuracy of the information contained in it. Similarly, the need for hardware and software for main and reserve production facilities is regularly clarified. Responsibility for maintaining, testing, updating and distributing the plan rests with the coordinator. Testing can be done in two stages: first testing each element of the plan, then simulating a disaster and testing the entire plan. However, costs remain a very important factor.
Management must assume that adverse events are inevitable sooner or later. In this regard, it is necessary to make expenses aimed at taking precautionary measures that will minimize the negative consequences of adverse events. These costs can be justified to some extent by using a contingency plan for marketing purposes: demonstrating to large customers that such a plan exists and is constantly being adjusted, thereby ensuring the smooth functioning of the bank in any circumstances.
It is widely believed that the cost of such planning should generally not exceed 1% of total data processing costs, but its specific amount is set in accordance with organizational policy.
Activity survey
Before drawing up a plan, it is necessary to conduct a survey of the bank’s activities to determine:
- a list of vital applied tasks and their priorities;
- a list of resources providing data processing and their priorities;
- potentially dangerous events and the likelihood of their occurrence;
- possible monetary losses in case of emergencies.
Possible hazardous events include:
- air conditioning system failure;
- electrical power failure;
- equipment failure;
- failure of the telecommunications system;
- flood;
- fire;
- civil unrest;
- vandalism or sabotage;
- theft;
- company picketing;
- emergency incidents that lead to damage to the building, equipment and materials;
- strikes;
- local military conflicts.
The plan should describe the specific actions that need to be taken in each of the circumstances selected as possible threats.
Indirect losses resulting from such external influences are difficult to quantify, but some potential sources can be identified:
- increased operating costs;
- loss of clients;
- loss of property;
- publication of unfavorable information;
- loss of profit;
- loss of prestige;
- loss of competitiveness;
- failure to comply with the requirements of laws and regulations.
Priority of applied tasks
To establish the order in which production problems should be solved with a limited number of resources, each of them must be assigned a priority.
The list of priorities could, for example, be like this:
- Priority 1 - tasks that must be completed according to the established schedule.
- Priority 2 - tasks that can be completed given the availability of time and resources.
- Priority 3 - tasks that should not be performed in the event of a disaster.
The final decision on priorities is made by management, taking into account the recommendations of the steering committee. Once they have been identified, it is necessary to indicate the resources required to complete these tasks (personnel, materials, equipment). All this data is entered into the contingency plan.
Operating conditions
The plan must indicate the resources necessary for data processing:
- hardware configuration;
- system configuration;
- teleprocessing network;
- software, including system, application and data transfer software;
- documentation (for programs, operation and user);
- personnel needs.
In this case, the future development of the data processing system must also be taken into account.
Storage of documentation and data outside the production premises
This is one of the most important parts of the plan! The backup storage location must be safe and remote from the main premises. The plan should include backup copies of the following documents and data:
- documentation for application systems, programs and operating systems,
- source texts of programs and object codes,
- procedure libraries,
- operating system libraries,
- main files,
- change files,
- forms of all input and output documents in sufficient quantities,
- contingency guidelines,
- accounting sheet of technical equipment,
- software.
When purchasing software packages, you should, whenever possible, purchase the program texts in the original language to protect yourself from unexpected cessation of business by the supplier.
Duration of emergency
An equally important factor is the length of the period of inactivity. It is necessary to provide options for different durations of system inoperability and for each of them develop its own action plan.
These options fall into three main categories:
- short-term inoperability (up to 6 hours);
- incapacity of average duration (from 6 to 24 hours);
- long-term inoperability (over 24 hours).
The specific length of the periods must be decided by management.
As a rule, short-term inoperability does not require moving to a reserve production facility, but entails a change in the work schedule of employees, equipment, transport, etc. However, sometimes it is difficult to estimate the period of inactivity. In this case, it is prudent to begin preparations for the move to the reserve production facility immediately so that it can be carried out quickly if necessary. To this end, management must continually monitor the situation and determine when to implement a higher category disaster plan. Advance warning of the implementation of another plan will make the transition to the next mode of operation smooth and make the work of those implementing it easier.
Data Center Restoration
Planning and executing the work involved in implementing a contingency plan requires a lot of effort. No less effort will be required to move back to the original premises; the same organization is needed here. To some extent, it can be said that the contingency plan is implemented twice: once when moving to the backup facility, and again when moving to the original location.
Each contingency plan is always developed taking into account the specific conditions in which the data processing system operates and the technical resources available. However, the plan should cover all the aspects listed above.
Developing and maintaining a contingency plan is an extremely painstaking, complex and responsible undertaking. However, these costs of labor and money cannot be considered wasted, because for banking systems, like no other, the principle “Time is money!” and the future of the bank may depend on the speed of restoration of their normal activities.
Conclusion
The leaders of an organization or company are the guardians of its interests. They must apply high-quality management methods that will ensure profit, proper quality of products and services, stability and development of the organization in the interests of customers, employees and investors. If an emergency situation can call into question the very existence of an organization, then its management is unlikely to cope with its responsibilities.
In the absence of an effective “Business Continuity Plan”, the following problems and dangers may arise:
- Interruption of an organization's activities, which entails an inability to service existing customers, loss of business prospects, a decrease in the existing circle of customers, loss of prestige and loss of competitiveness.
- Financial damage due to the inability to process accounts receivable, late payment penalties, lost discounts, failure to update account balances, and lost or unaccounted for sales.
- Legal liability due to failure to fulfill contractual obligations.
- Termination of the organization's activities.
"Continuity planning" refers to "identifying and protecting critical business processes and resources necessary to maintain the organization's operations at the desired level, and developing procedures that will ensure the organization's survival if its normal operations are disrupted."
To ensure smooth operations, it is necessary to take into account all interrelated external and internal functions, including manual methods of accounting and information processing.
The objectives of the project to develop a plan to ensure continuity and recovery of the organization's operations in the event of disasters are:
- A business process assessment that will ensure the plan is developed using a well-structured and comprehensive methodology.
- Develop a cost-effective and workable plan that will ensure continuity of critical business processes in the event of a major disruption to the organization.
- Minimizing the consequences of any disaster for the organization.
An effective business continuity plan is a relatively inexpensive form of insurance for companies against the consequences of possible disasters, and the cost of it should be considered as part of the necessary costs of maintaining the normal functioning of the organization.
. Sources of information on issues related to ensuring uninterrupted operations of organizations in the event of disasters
Currently, in Russia there is no state organization that systematically deals with the dissemination of knowledge in the field of ensuring the uninterrupted operation of organizations and companies in the event of disasters. At the same time, there are many WEB servers on the Internet dedicated to this issue; we will list only a few of them:
- http://www.bcp.ru - Russian-language information portal on management and business continuity planning. It was created and conducted by certified specialists in the field of business continuity management (MBCI qualification according to the International Business Continuity Institute). In England, the Business Continuity Institute, BCI, http://www.the bci.org, from the Russian representative office of KPMG, as well as audit and control of information systems (CISA qualification according to the International Association of Audit and Control of Information Systems), Information Systems Audit and Control Association, ISACA, http://www.isaca.org.
http://www.dr.org - server of the International Institute for Disaster Recovery (Disaster Recovery Institute International - DRI International, formerly DRI).
The Disaster Recovery Institute International (DRI International) was established in 1988 at the University of Washington. It is a non-profit organization that provides training and credentials in the areas of post-disaster recovery.
The main activities of the institute are:
- creation of an appropriate Common Body of Knowledge and dissemination of information;
- initial training in the field of ensuring uninterrupted operations of the organization in the event of a disaster;
- continuous professional development of specialists;
- acting as the leading organization for the examination of relevant standards.
http://www.drj.com - server of an independent American journal on disaster recovery issues (Disaster Recovery Journal).
Disaster Recovery Journal, or DRJ, is a disaster recovery journal published since 1987. It has over 40,000 subscribers and contains almost 100 pages.
Since 1989, DRJ has held annual conferences. Currently attended by over 2,000 people from all over the world, these conferences are the largest in the field.
The DRJ Web server, in addition to articles from the last two issues of the journal, contains a lot of useful information: a teleconference, a description of products and consulting services, a list of companies and organizations working in the field under consideration, a list of Web servers on this topic, etc.
http://www.fema.gov - server of the US Federal Emergency Management Agency (FEMA).
The server has a section dedicated to the problem of reducing the harmful effects of disasters, information about past disasters, teleconferences on various topics, information about conferences and seminars, a list of training courses conducted by FEMA, reference literature, etc.
- http://www.iaem.com - server of the International Association of Emergency Managers. It is a non-profit educational organization that disseminates knowledge on methods of saving lives and property in emergency situations.
- http://www.sba.gov/disaster - section of the US Small Business Administration server dedicated to business continuity planning.
If you blindly trust the reliability of your hard drive, then trust
the day will come when you will regret it. Any mechanical
system (and the hard drive is one) has its own reserve of durability
sti. Nobody can predict exactly what will happen after the resource is depleted.
will say, but you can’t count on the best: the most important for you
the information will probably be lost forever. On Windows NT Server
built-in mechanisms to ensure system fault tolerance:
for particularly reliable disk operation, backup, support
support for working with uninterruptible power supplies, selecting operating
capable configuration and recovery of the system with specially
th disk. But what if the computer itself fails? To this
did not affect your work, recommended cluster solutions.
As you can see, the system has quite a lot of means to ensure security
fighting work. Perhaps someone will even ask: why so many times?
new, at first glance, duplicating each other mechanisms - after all, this
increases the cost of the system? Why do clusters provide
such a high degree of reliability, why not use them everywhere?
Table 5-1 shows the different types of failures that can occur.
walking on enterprise networks, as well as methods for preventing them or
minimizing unpleasant consequences.
| Table 5-1 | ||
| Source of failure | Cluster solution | Other solutions |
| Network hub | Applicable if everyone | - |
| of nodes connected | ||
| to your hub | ||
| Supply voltage | - | The source is uninterrupted |
| slaughter food | ||
| Connecting to the server | Applicable | - |
| HDD | - | RAID, fail-safe |
| resistant discs | ||
| Server hardware | Applicable | - |
| (processor, memory | ||
| and etc.) | ||
| Server software | Applicable | - |
| Routers, | - | Duplicate |
| leased lines, etc. | routes and lines | |
| Switched | - | Modem pools |
| connections | ||
| Client | - | Several clients |
| computers | with the same | |
| access levels | ||
The table clearly shows that although clusters provide high
what degree of server reliability, but are not a panacea. Besides
they are only supported by the enterprise version (Windows NT
Server Enterprise Edition). Additional mechanisms are required. Ras-
look at the means of ensuring uninterrupted operation built into
Windows NT Server 5.0.
Means for increasing operational reliability
with disk
If you regularly used programs such as CHKDSK or
Norton disk Doctor, you probably paid attention to sometimes detecting
“bad blocks” located on hard drives, which
these programs are marked as unavailable. The reasons for the appearance of such
There are several areas, ranging from a low-quality disk to some
other types of viruses. But whatever the reason, the result is all
where one is a reduction in the available working space on the disk.
If you do not diagnose the disk in a timely manner, then the consequences
could be even worse: You will lose data recorded on your phone.
damaged area, and, in the worst case, the operating system
will lose functionality. Therefore, if your computer only has
to one hard drive or you do not use the technologies described
later in this chapter, the first concern should be the regular maintenance
Checking the disk status.
Comment. Modern computer systems manufactured from
well-known manufacturers, often have built-in tools -
we monitor the status of disks and alert the operating system
topics and administrator about the impending threat. An example would be
live Compaq Proliant computers, where about the impending disk crash due to
not only the operating system, but also the operator broadcasts to the pager
which sends a warning signal.
Checking the status of the hard drive
To check the hard drive, use the built-in CHKDSK utility,
launched from the command line. To find bad sectors you need
You need to run it with the /R switch. However, it should be remembered
that the operation could take several hours. But if you produce
regularly, then you can indirectly judge the presence of bad sectors
due to the sharply increased verification time.
CHKDSK [[ path ]filenanie] ],
Indicates the disk to be scanned;
Filename - specifies files to check for fragmentation (only on
FAT);
. /F - corrects errors on the disk;
. /V - for FAT, shows the full name and path to the files on the disk; For
NTFS - also cleanup messages;
. /R - identifies bad sectors and restores readable information
formation;
. /L: size - NTFS only: sets the log file size to
kilobytes, if the size is not specified, active is assumed.
Attention! If, while the system is running, program execution
CHKDSK is not possible (for example, the selected drive contains a file
swap), you will be asked to reschedule its execution at the moment
system boot. If you agree, then the next time you reboot
A full scan of the disk will be performed.
In addition to the CHKDSK command in Windows NT 5.0, there is
There is a graphical utility. To call it, you need to click
right-click the drive name in the My Computer folder and in the appeared
Xia menu select command Properties.
In the dialog box you need to select
tab Tools
and click the button Check Now.
For a complete check
disk, both checkboxes should be checked: Automatically fix file system
errors And Scan and attempt recovery of bad sectors.
Dialog box to check the status of hard drives
To protect yourself from all sorts of troubles associated with
disk system failures on the server, it is better to use tools
increasing the reliability of their operation. To Windows NT tools, providing
that provide increased reliability when working with disks include:
disk mirroring, disk duplication, disk striping with con-
parity check and sector replacement (in "hot" mode).
RAID technology (redundant array
inexpensive disks)
Means for increasing the reliability of working with disks are industrially
standard and are divided into several levels of use
redundant arrays of low-cost disks (RAID) (see Table 5-2).
Each level has a different combination of performance
ity, reliability and cost. Windows NT Server 5.0 provides
support for RAID levels 0,1 and 5.
Disk striping
This level (RAIDO) provides interleaving between different
disk partitions. In this case, the file seems to be “spread out” over several
physical disks. This method can increase productivity
difficulty working with the disk, especially when the disks are connected to different
disk controllers. Since this approach does not provide excess accuracy
However, it cannot be called a full RAID. In case of failure
of any partition in the array, all data will be lost. For implementation
method requires from 2 to 32 disks. Increase in productivity
is only achieved when using different disk controllers.

Level O: Disk Striping
Disk mirroring and duplication
A mirror copy of a disk or partition is created using RAID level 1:
mirroring or duplication. Disk mirroring is effective
Applies at the partition level. Any partition, including boot or
systemic, can be mirrored. This is the simplest method
increasing the reliability of disk operation. Most often, mirroring -
the most expensive method of ensuring reliability, since it involves
Only 50 percent of the hard drive capacity is used. However, in
Most peer-to-peer or small server networks
The method is cheap due to the use of only two disks.
Disk duplication - mirroring using additional
th adapter on the secondary drive - provides fault-tolerant
This is true both when the controller fails and when the disk fails. In addition, duplicate
tion can improve productivity.
Like mirroring, duplication is done at the partition level.
For Windows NT there is no difference between mirroring and dubbing.
linging - the only question is the location of the other section.
It is appropriate to stop here and clarify the situation with which we are satisfied
but administrators often encounter system mirroring
boot disk. It happens that when one of the dis-
kov, a decision is made to operate the system with another, leaving
we're talking. It is assumed that since the second disk is
mirror copy of the first one, then no additional measures should be taken
There is no need to download - just boot your computer. This is where
there is a stumbling block: if this disk partition is not
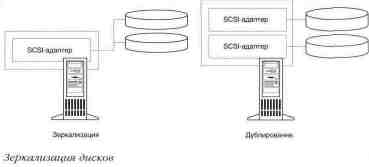
To activate the partition, you must use either the FDISK utility,
included with any version of MS-DOS (for FAT partitions), or
Disk Administrator nugget.
Alternation of disks with correction code recording
RAID level 2 works like this: when a data block is written to a disk, it is split
is divided into several parts, each of which is recorded on a separate
nal disk. At the same time, a correction code is created, which also records
dumped onto different disks. Lost data can be recovered by
correction code using a special mathematical algorithm.
This method requires allocating more disk space for storage
correction code than for parity information. On Windows NT Server
this method is not used.
Alternation of disks with correction code recording
as parity
RAID Level 3 is similar to Level 2 except that the code
rection is replaced by parity information written to one disk.
This way, disk space is used better. On Windows
NT Server also does not apply this level.
Alternating disks in large blocks.
Storing parity on one disk
RAID Level 4 writes entire blocks of data to each disk in the mass
sive. A separate disk is used to store information about the
ness. Whenever a block is written, the parity information must
be read, modified, and then written again. This method is more
suitable for large block write operations rather than for processing trans-
shares It does not apply to Windows NT Server.
Alternating disks with recording information
about parity on all disks
RAID level 5 is used in most modern fault-tolerant
smart systems. It differs from other levels in that the information
The parity information is written to all disks in the array. At the same time, the data and
their corresponding parity information is always located on
different disks. If one of the disks fails, the remaining
There is enough information for complete data recovery.
Disk striping with parity provides the highest performance
performance of read operations. But if a disk fails, the speed
readings drop sharply because recovery needs to be done
data. Due to the circulation of parity information of the write operation
require three times more memory compared to regular recording.
This mechanism supports from 3 to 32 disks. Into the alternation set
may include all partitions except the boot (system) partition.
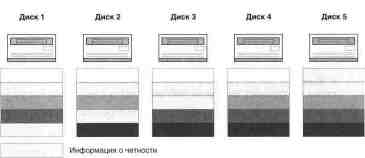
Level 5: Disk Striping with Parity
When using a RAID5 array in clusters as a general
resource (this will be discussed in more detail later) the greatest reliability
efficiency and productivity are achieved when each
drives is connected to its SCSI controller.

Connecting a RAID array to a cluster
Basic and dynamic disk volumes
Windows NT 5.0 introduced new concepts: basic And dynamic
volumes You can perform the following operations on basic disks:
Create and delete primary and extended partitions and logical
rims;
Mark the section as active;
Delete volume sets;
Break up mirroring in a mirror set;
Restore mirror sets;
Recover sets of striped disks while preserving information
parity formations;
Make disks dynamic;
Convert volumes and partitions to dynamic ones.
Some operations can be performed only on dynamic dis-
kah, namely:
Create and delete simple volumes, mirrored volumes, striped volumes
and RAID-5;
Expand volumes;
Remove a mirror from a mirrored volume;
Repair mirrored volumes;
Fix RAID-5 volumes.
To turn a disk into dynamic, select it in the console nugget.
Select Disk Management and right-click. IN
select the command from the context menu Initialize Disk.
Next follow
program instructions.
The first beta version of Windows NT 5.0 does not support conversion
Converting disk partitions to dynamic ones. This opportunity will be realized
van in the second beta version.
Attention! Dynamic disks are not accessible from MS-DOS or Windows.
Hot swapping sectors
In Windows NT Server, you can recover sectors during operation.
You. When formatting a volume, the file system checks all sec-
ra and, having detected defective ones, marks them for exclusion from further
our work. If a bad sector is detected during the writing process (read
niya), the fault-tolerant driver tries to transfer data to another
sector, and mark the first one as faulty. If the transfer is successful, the file
The system does not warn about the problem. This procedure is possible
only on SCSI drives.



1. Determines the bad sector
2. Moves data to a good sector
3. Marks the bad sector
Replacing sectors
Error correction
The described capabilities of fault-tolerant configurations provide
are displayed when installing the FTDISK driver on the system. In general, it is possible
the ability to detect and correct disk errors determines
are influenced by a number of factors. Table 5-3 lists possible variations
configuration ants and the corresponding possibilities for “working on
mistakes."
| Table 5-3 | ||
| Description | Failover Volume | Regular volume |
| FTDISK installed; | FTDISK | FTDISK |
| hard drive type | restores | does not restore |
| SCSI; reserve | data | data |
| sectors in stock | ||
| FTDISK replaces | FTDISK reports | |
| bad sectors | file system | |
| about the bad sector | ||
| The file system is not | NTFS remaps | |
| aware of the error | clusters; during | |
| read data is lost | ||
| FTDISK installed; | FTDISK | FTDISK |
| hard drive type | restores | does not restore |
| non-SCSI; reserve | data | data |
| no sectors | ||
| FTDISK sends | FTDISK reports | |
| data and message | file system | |
| about the bad sector | about the bad sector | |
| file system | ||
| NTPS remaps | NTFS remaps | |
| clusters | clusters; during | |
| read data is lost | ||
| FTDISK is not installed; | - | The disk driver reports |
| any disk type | file system | |
| about the bad sector | ||
| NTFS remaps | ||
| clusters; during | ||
| read data is lost | ||
Backup
Windows NT 5.0, just like previous versions, has built-in
using a backup program. However, the new version is different
comes with a number of functionalities, including
name support for different types of backup media (not
magnetic tape only), built-in ability to compile schedules
backup scripts, backup wizard program
(recovery), as well as a new user interface.
Windows NT Backup Program
Windows NT Backup allows users to perform backup
copying and restoring data to a local drive on
magnetic tape (streamer), on any hard or floppy disk, on
storage device on magneto-optical disks and, in general, on any
a storage device supported by the operating system
system. Let's list the main features of the program:
Backup and restore data located
on NTFS, FAT and FAT32 partitions both local and remote
computer;
Selecting individual volumes, directories or files to be copied
recovery (recovery), as well as viewing detailed information
tions about files;
Selecting the media to which the backup will be performed
roving: magnetic tape, disk, floppy disk, magneto-optical
carrier, etc.;
Selecting an additional check for the correctness of the recording (restoring
updates);
Normal backup operations: normal,
copying, incremental, difference
tial), daily (daily);
Placing several records on one medium and combining them
tion or substitution;
Create a batch file to automate backups
vania;
Scheduling backup operations over time;
Browse the complete backup directory and select files and
directories to be restored;
Selecting the destination drive and directory to which to execute
recovery;
Using the backup wizard (restore)
formation);
Saving information about backup operations (recovery)
leniya) in the log and its subsequent viewing in the Event Viewer.
Program interface
If in previous versions of Windows NT there is a reserve for starting a program
copying required finding the corresponding icon in the group
no administrative tools, then access to it is now carried out
similar to Windows 95- Right-click the icon-
choke corresponding to the hard drive and select from the context menu
Properties command and then in the dialog that appears Disk Pro window
perties
- tab Tools.
Then click on the section Backup
Backup now button
and the backup program window will appear on the screen.
th copying.
Attention! For backup, it is necessary that the system
The Media support service was launched on this topic. In the first beta version
Windows NT 5.0 it does not start by default. Run it through
Service Management console snapshot.

Windows NT Backup Interface
On the left side of the window you can see the device tree of your computer.
yuter and the network to which it is connected. The right side shows the sleep
juice of folders and files located in the folder you selected. At the bottom
part of the window, you can specify the type of media on which you will perform -
All backups, backup type, parameters.
There is also a button there Schedule
with which you can pro-
view the existing copy operation schedule.
If you are sure that you know what parameters and how to
give, then you can safely get to work. If not, use it
an invitation that appears above the described program window, and
select the desired wizard program.

Prompt to start backup
Backup options
(recovery)
To available backup (restore) options
relate:
Backup type;
Logging parameters;
Files that cannot be backed up;
Recovery options.
To define these parameters, either click the button Options
V
at the bottom of the program window, or select the command of the same name
on the menu Tools.
A dialog box will appear on the screen Options.

Dialog window Options tab Backup Type
You can choose whether to back up all your marks.
named files (All selected files)
or only new or modified
(New and changed/lies only).
In the first case, all selected files are copied (even those that
for example, were already copied a few days ago and have not been copied since then
have changed). It is clear that the reservation execution time in a given
In this case, it depends only on the total volume of the marked files. You
It is also possible to set the switch to the position
instructing to mark file modification (Normal backup type.
Backup all files. Clear the modified/lag.)
or don't do it (Copy
backup type. Backup all files. Don't clear the modified flag.).
Second
type allows you to significantly reduce backup time.
In addition to differential reservation and incremental reservation
We provide effective daily backups. At the same time I copy
Only files whose creation or last modification
dated today.
Logging backup information is required
to monitor this procedure, monitor error messages,
problems and finding out their causes. Settings for logging in the task log
appear in the same dialog box Options
on the tab Backup logging.

Dialog window Options tab Backup logging
By default, it is suggested to log only the most
summary details: loading tape, starting backup
copying error, file access error, etc. You can either specify
Please note that all events must be recorded (including names
files and directories), or refuse logging altogether. Here
example of an entry without details;
Operation: Backup
Active Device; File
Media Name: "Media created on 11/15/97"
Backup set ft1 on media Ш
Backup Method: Normal
Backup started on 11/15/97 at 16:03.
Backup completed on 11/15/97 at 16:03.
Directories: 2
Files: 5
Bytes: 21,192
Time: 1 second.
Operation: Verify After Backup
Verify Type: Cyclic Redundancy Check
Active Device: File
Active Device: D:\WINNT5\SYSTEM32\Backup.bkf
Backup set HI on media ff1
Backup description: "Set created on 11/15/97 at 16:03"
Verify started on 11/15/97 at 16:03.
Verify completed on 11/15/97 at 16:03.
Time: 2 seconds.
Operation: Restore
Restore started on 11/15/97 at 16:05,
Warning: File New Bitmap Image.bmp was skipped
Warning: File New Rich Text Document, rtf was skipped
Warning: File New Text Document.txt was skipped
Warning: File New WordPad Document.doc was skipped
Warning: File tracking,log was skipped
Restore completed on 11/15/97 at 16:05.
Time: 3 seconds.
The time it takes to complete a backup is not particularly important.
tion if the file size is not large. However, with daily reservation
storage of files and directories on several corporate servers, shared
volume of disk space, which can be hundreds of gigabytes
bytes or even terabytes, a whole may not be enough for copying
nights. One way to reduce time is to exclude
the process of copying files that are not modified at all, or
rarely and from a centralized source. For example, in system ca-
There can be many files of fonts, cursors, pictures, etc. in the logs.
To exclude such files from the list of copied files, select in the
log window Options
tab Exclude Files
and specify extensions
all files for which you do not need to make a backup copy.
Dialog window Options tab Exclude files
Restoring files is not a very complicated task.
whose, but requires careful attention. It is possible that the files
stored on disk contain more recent information than recorded
sled in the archive. By restoring data from the archive to the existing one,
you will irrevocably lose what has been done since the
last reservation.
That is why it is not recommended to replace files on the stored disk.
mi in the archive by default. You have a choice: replace only those files
files whose date is older than the date of the archived files; or replace everything
files without parsing.

Dialog window Options tab Restore options
Performing a Backup
Once you have defined your backup settings, you can
go directly to the procedure itself.
Attention! If you are backing up to a file, then specify
destination file name. This file will be called hereafter But-
media despite the fact that in the physical sense it is not manifest-
is placed on the carrier, and itself is located on the carrier, for example, on a
on this disk. The term "media" should not confuse you when the program
Ma asks a question like “Replace the entire contents of the media?”. Speech in
In this case, we are talking only about the destination file.
To start the backup, click the button Start
in the program
me Windows NT Backup. A dialog box will appear Backup Information
tion
suggesting to clarify some additional parameters.

Dialog window Backup Information
The following window elements will help you set parameters:
Checkbox Restrict access to owner or administrator
- if he is from-
marked, then access to the media will be denied to file owners
or administrators;
Checkbox Backup local Registry
- if it is checked, it will be created
backup copy of the registry on the local machine;
Field Set description
- you can enter the name of the reservation in it -
managed information; upon restoration, this name will be re-
numbered in the list of available sets;
. flask Append this backup to the media -
By checking it, you indicate
inform the program about the need to add new information to
already stored in the archive;
Checkbox Replace the data on the media with this backup
- mark-
tive it, you will indicate to the program the need to replace all
previous information on a new medium; in case of using
a new medium will be created as a magnetic tape carrier.
recording and data will be recorded from the beginning of the tape if you use
calling a file on disk - the contents of the file have been overwritten;
In field Use this media name you must enter the media name;
Button Advanced
opens up the possibility of introducing additional
options in the dialog box Advanced backup options
Dialog window Advanced Backup Options
Using the dialog box
Advanced Backup Options
You can
demand:
Perform a directory service backup;
Perform a backup copy of hierarchical storage data;
Check data after reservation;
Use compression at the hardware level (if allowed)
your equipment);
Select one of the previously described backup types.
After determining all the listed parameters, the process will begin
backup files to the specified media.
Backup planning
In previous versions of Windows NT, reserve time scheduling
for a clear copy, it was necessary to use the system scheduler
(AT command). The new version has a built-in scheduler that
allows you to set the initial day and time of the reservation, indicate whether
Is this operation regular, if so, with what periodicity?
completeness and for how long it should be carried out. All these couples
meters are set for each backup in the dialog
window Scheduled Job Options.

Dialog window Scheduled Job Options
For example, if you want to back up your home
them user directories every night, then by creating the appropriate
reservation task, define for it:
. Start date - current number;
. Start time -
12:00 (hoping that at midnight" all users will already
went home, where they rest, and do not work with files in their
their home directories);
Check the box Run more then once,
. Frequency - daily (daily) interval - 1 day.
You should also specify the account that has access to this account.
data for backup. This account must have
corresponding privilege.

Schedule backup jobs
The program indicates midnight "American style", that is, at 12.00 AM.
The result should be the schedule shown in the previous
next drawing. There is also another task on this graph,
performed every Monday.
Source support
uninterruptible power supply
Uninterruptible power supplies (UPS) support the operation of
ability of the system during power failures due to battery energy
batteries Windows NT has a built-in UPS service that allows you to
certain actions in the system upon receipt of signals from the source
uninterruptible power supply. In addition to the built-in service, third-party
UPS manufacturers offer additional products that provide
providing greater functionality.
The UPS Windows NT service detects power supply failures, warning
informs the user about them and correctly shuts down the system when powered
Replacement of the backup power source.
The parameters of this service are configured in the UPS section of the pa-
no control.
UPS Settings Dialog Box
Customizable parameters include:
The serial port to which the wireless source is connected
slaughter food;
Signal from UPS in case of power failure;
Warning from UPS when battery charge level drops;
Signal from the UPS service to turn off the uninterruptible source
nutrition;
A batch file executed before shutting down the computer;
Expected battery operating and recharging time;
Time intervals for warning messages.
The UPS service must be used in conjunction with the Alerter, Mes-
senger and the Logbook. Moreover, all events associated with
UPS service (for example, power failure or power connection failure)
uninterruptible power supply) will be recorded in the log book,
and certain users will be notified about them over the network. From to
by the power of the parameter Server
on the control panel you can assign
users and (or) computers that will receive these
homework.
Server clusters
In general cluster is called a group of independent systems,
working as one. The client interacts with the cluster as
with one server. Clusters are used both to increase access
ness, and for scalability.
Availability. When a system in a cluster fails,
cluster software distributes the work performed
I communicate with this system between other systems in the cluster.
As an example, consider the operation of a modern supermarket.
The heart of this business is the clearinghouses. Cash registers must
We need to be constantly connected to the store database storing
information about products, codes, names and prices. If the connection breaks,
the opportunity to serve clients is lost, reputation deteriorates
trading organization, profits fall.
Cluster technology will increase system availability. You can offer
live use of two systems connected to a multiport
disk array on which the database is located. When
server A failure, the backup system (server B) automatically “pick-up”
tit" connection so that users will not even notice what happened
failure. Thus, the combination of technologies to provide increased
high reliability of disk operation, standardly used in Windows
NT Server (striping, duplication, etc.) with cluster technology
it guarantees the availability of the system.

Scalability. When the total load reaches its maximum capacity,
of the systems that make up the cluster, the latter can be increased,
adding an additional system. Previously, users had to
began to purchase expensive computers that would allow
install additional processors, disks and memory. Clusters
allow you to increase productivity by simply adding new ones
systems as needed.
As an example of scalability, consider a typical situation
in financial business. Full responsibility for the work of financial
owl or banking network is the responsibility of the chief technical specialist. He
understands perfectly well that the slightest failure of the system will entail
colossal financial losses and a hail of reproaches against him. If
system works flawlessly, then gradually the
more and more tasks will arise, and, undoubtedly, one day it will be possible
The system's capacity will be exhausted. Requires development and creation
new system.
Until recently, such considerations led to the conclusion that
technical specialists of large banks, forced to order in advance
adapt" to the enormous increase in computing needs, creating
systems based on large mainframes and minicomputers were created.
Cluster technology based on Windows NT Server provides
tremendous opportunity - to abandon expensive equipment
tion and use a widespread system on the most common
different hardware platforms. The power of the cluster is being increased by
by simply adding another system to it.

Cluster scalability
Traditional Delivery Architecture
high availability
Today, to increase the availability of computer systems, we use
There are several approaches. The most typical method of duplicating systems is
themes with fully replicable components. Software
The cookie constantly monitors the state of the running system, and
the second system is idle all this time. If the first system fails,
We are switching to the second one. This approach, with one hundred
ron, significantly increases the cost of equipment without increasing
performance of the system as a whole, and, on the other hand, does not guarantee
errors in applications.
Traditional provisioning architecture
scalability
To ensure scalability today, several
to approaches. One way to create a scalable system
performance - using symmetric multiprocessing
weed treatment (SMP). SMP systems use multiple processors
share memory and I/O devices. In traditional
model known as the shared memory model,
one copy of the operating system is running, and application processes
All tasks work as if there was only one processor in the system. At
running applications on such a system that do not use shared data,
a high degree of scalability is achieved.
The use of systems with symmetrical processing is inhibited, mainly
nom, physical restrictions on bus speed and access to pa-
wrinkle. As the speed of processors increases, their
price. Today, a user who wished to add to the configuration
tion of two to four processors (not to mention more) should
pay a significant amount, completely disproportionate to your
year, obtained from increasing the number of processors.
Cluster architecture
Clusters can take different forms. For example, as a cluster
can be several computers connected via an Ethernet network.
Example of a high-level cluster - high-performance multi-
processor SMP systems interconnected with high-speed
no communication and input/output bus. In both cases, the increase in computation
productive power is achieved gradually by adding another
systems. From the client's point of view, the cluster is represented as a single
th server or image one system, although in reality it consists of non-
how many computers?
Today, clusters use mainly two models: with common
disks and without common components.
Shared drive model
In the shared disk model, the software executable
on any of the systems included in the cluster has access to system resources
cluster stem. If two systems need the same data, then
The latter are either read twice from the disk or copied from one
stems to another. On SMP systems, the application must synchronize
and turn access to shared data into a sequential form. Usual
but plays an organizing role during synchronization distribution manager
distributed locks DLM (Distributed Lock Manager). DLM service
Allows applications to monitor access to cluster resources.
If more than two systems access the same resource at the same time,
then the dispatcher recognizes and prevents a potential conflict.
DLM processes may result in additional communication schedule
network problems and reduce performance. One way to avoid
this effect is the use of a software model without common comm-
ponents.
Model without common components
In a model without common components, each system in the cluster
owns a subset of the cluster resources. At a specific moment in time
Only one system has access to a particular resource, although
in case of failures, another dynamically determined system can take over
ownership of this resource. Requests from clients are automatically forwarded
are directed to systems that own the necessary resource.
For example, if a client request contains a resource request,
owned by several systems, one system selects
to serve requests (it is called the host system). Then this
the system analyzes the request and transmits subqueries to the appropriate ones
systems. They execute the received part of the request and return the response.
the result to the host system, which generates the final result and
sends it to the client.
A single system request to the host system describes a high-level
new function that generates system activity, and intraclass
Terrestrial traffic is not generated until the
van the end result. Usage of the application, distributed
between several systems included in the cluster, allows
overcome the technical limitations inherent in a single computer.
Both models: both with a common disk and without common components, can
used within one cluster. Some programs
best use the capabilities of a cluster within the framework of a model with
with a big disk. Such applications include tasks that require information
intensive access to data, as well as tasks that are difficult to separate
pour into pieces. Applications for which scalability is important, rational
It is better to perform it on a model without common components.
Clustered application servers
So, clusters provide accessibility and scalability for everyone
server applications. In turn, special "cluster"
applications can take full advantage of clusters. Servers
databases can be improved by adding either features
coordination of access to shared data in clusters with a shared disk,
or functions for dividing queries into simpler queries into a class
terah without common components. In the latter, the database server will be able to
take full advantage of data sharing through parallel
ny requests. Additionally, server applications can be distributed
expanded with functions for automatic detection of idle computers
components and initiate rapid recovery.
Historically, clustered applications were built using
transaction processing monitors. The transaction monitor is responsible for
redirecting client requests to the appropriate servers
within the cluster, distribution of requests between servers and coordination
a nation of transactions between cluster servers. Transaction Monitor
can also handle load balancing, automatic transfer
reconnection and repetition of request execution in case of failure
server, and also take part in the recovery process after
failures.
Windows NT cluster models
The current implementation of clusters for Windows NT supports
two servers interconnected in a special way. If on one
one of the servers fails or is disconnected, then the second one starts
perform his functions. In addition, clustering provides a basis
load balancing, distribution of processes between servers. By
the principle of adjustment to the use of certain properties, cluster
Windows NT systems can be divided into five models:
. model 1- high availability and static balancing on-
loads;
. model 2 - “hot standby” and maximum availability;
. model 3- partial clustering;
. model 4- virtual server only (no switching);
. model 5- hybrid.
Let's take a quick look at these models.
Model 1: High Availability and Static
load balancing
This model provides high availability; as well as production
performance: acceptable - with one non-working unit, and high
kaya - with both workers; as well as maximum use
hardware resources.
Each of the two nodes provides its own set of
resources in the form of virtual servers that clients have access to
ents. The performance of each node is selected in such a way that
which provides optimal performance for resources, but
only as long as both nodes are operational. If one fails
server, the execution of all cluster resources is switched to another
goy, productivity drops sharply, but all resources are
are still available to customers.

Model 1 configuration
For example, this model can be applied when sharing
transferring files and printers. On each of the nodes, independent
shared groups with file and printer resources. If one fails
Of the nodes, the remaining node takes over all management of its resources. Pos-
After recovery, the node returns its part of the work, As a result,
In this case, clients have constant access to both all file resources
the cluster itself, and to all print queues.
Let's look at another example of using this model. Let's say on
the enterprise has a mail server on which Mic-
rosoft exchange. At peak load times the server cannot cope and
turns off. Since the post office must function continuously,
The following solution can be proposed. The server on which the execution
Microsoft Exchange is formed, united into a cluster with a server on which
rom the data access application works in normal mode. IN
when the mail server fails, its role is temporarily assumed
second server in the cluster. But, I emphasize, this is only temporary, and immediately
after rebooting the main mail server, all work is completed
The mailbox is handed over to him again. Similarly, re-
Switching the database program.
Model 2: "hot standby"
and maximum availability
This model ensures maximum availability and production
driving ability, but due to investments in equipment that
part of the time is idle. One of the cluster nodes, called per-
vicious serves all clients, while the second one uses -
as a "hot reserve".
When the primary node fails, the second one immediately
starts services running on the first one, and at the same time provides
performance as close as possible to the performance of the original
vicinal node.

Hot standby model
This model is best suited for the most important
organizing applications. For example, this could be a Web server,
serving thousands of customers and providing access to critical
our information. In this case, the cost of a node on duty
me "hot reserve", is still significantly lower than the losses possible
in case of termination of access to data.
Model 3: partial clustering
This model allows you to use it on servers that make up the
eraser, applications that will not be switched to
in case of failure. The resources of such applications are located not on a common, but
on the local server disk. In case of server failure, these applications
become inaccessible.

Partial clustering model
This model is suitable if applications running on one of the servers
faiths included in the cluster are not used often and their constant
accessibility is not so necessary. For example, it could be some
or an accounting application or calculation task.
Sometimes it happens that the switching model provided by Microsoft
Cluster Server, not suitable for some applications. (For example, when
execution of a computational task, switching from node to node is the same
will interrupt the calculation process). For such applications you need
other specific mechanisms to ensure uninterrupted operation.
Model 4: virtual server only
(without switching)
Strictly speaking, this model can hardly be called a cluster. It uses
There is only one server, which cannot be switched in case of failure.
is filling up.
On the other hand, all resources are organized in such a way that for the user
They appear as resources of different virtual servers. By-
this, instead of searching for the necessary resources on various servers on the network
the user accesses only one.
If the server fails, the cluster software starts
necessary services in the specified order immediately after reboot.
In the future, such a node may be connected to another for organizing
full cluster.

Single virtual server model
Model 5: hybrid solution
The latest model is a hybrid of the previous ones. In fact, with sufficient
With no power reserve, you can take advantage of the advantages of all models
in one and provide a variety of switching scenarios in case
failure.
The figure shows a possible example of a hybrid solution in which
In addition, both cluster nodes have switchable resources, non-switchable
switchable applications and services, as well as virtual servers.
Hybrid solution
Installing Microsoft Cluster Server
Installing clustering support software is very
Just. Running the installer on two computers will take
You have meth for no more than 10 minutes. However, as in any business, seven is better
measure once and cut once. In this case this means that
Before installing the software, you must carefully observe certain
initial conditions and configure the servers accordingly
way.
Before you start
To install MSCS (Microsoft Cluster Server), you must have the following:
operating equipment.
1. Two computers arbitrary configuration. Characteristics
computers may vary. For example, one has a processor
Pentium Pro with a clock frequency of 200 MHz, RAM capacity - 256 MB, built-in
Encrypted hard drive with a capacity of 2 GB. The second is a Pentium II processor with
clock frequency 233 MHz, RAM capacity 6MB and built-in hard
1 GB disk. The spread of characteristics is determined by the use
my model: from almost identical (for the "hot-
why reservation") to completely different (for the hour-
tical clustering).
2. Every computer should have at least one SCSI adapter
tera, to which shared drives will be connected. To these adapta-
frames there is one strict requirement: they must provide
create an operating mode that allows you not to initialize
bus when rebooting. In some cases, for this purpose it may be necessary
Try to disable the adapter BIOS.
Another requirement is that the SCSI ID of one of the computers
the ditch must necessarily be equal to six, and the other - seven.
The issue of termination deserves special consideration.
tires. It must be carried out in such a way that there is no
depend on the performance of any of the computers. By this
For this reason, the internal terminators of the SCSI adapter are not suitable. Ter-
minators must be outside. We can offer two options:
Option with the location of shared disks:
between servers;
at one end.
In the first case, there is a connection to servers at both ends of the bus
must be carried out using so-called Y-cables.

Communication with storage staging devices
In the second case, two servers are connected to each other so that the server
more distant from shared drives, connected using Y-card
white, and the disk drive using a regular cable, but
has either internal termination or a special connector for
connecting an external terminator.

Linking servers with shared drives at one end
3. At least 2 network cards in every computer. Nodes in a cluster
must be connected to each other by a reliable channel called
interconnect. Through this channel they exchange -
sharing information with each other about their condition. Suppose in
As such a channel, the same network card is used as
and to access cluster resources. In this case, there is a high probability
that when the network is loaded, false alarms will occur
introduction of the switching procedure. With both servers working,
information about their condition simply will not reach one
to another. As a result, both servers initiate the process of re-
decisions, which will most likely lead to system failure.
That is why it is recommended to use for interconnection
separate network channel. For higher reliability it is desirable
but organize several such channels. In any case, consider-
those that are more expensive for you: the cost of information lost for a while
tions or the cost of several network cards.
Interaction between clusters is carried out using the protocol
TCP/IP. Therefore, you will need to assign addresses for network cards
interconnect. For this purpose, you can use special
reserved addresses:
10.0.0.1 - 10.255.255.254;
172.16.0.1 - 172.31.255.254;
192.168.0.1 - 192.168.255-254.
4. Shared disks on servers must be assigned the same
letters. For example, if one of the servers has local disks
there are letters C, D and E, and in the other - C, D, E, F and G, then the first common disk
in both systems must be drive H.
Attention! All shared drives must be in NTFS format.
Assigning drive letters is done one at a time. First load-
One server is installed, and the second remains turned off. With the help of blind
When Disk Management is assigned the required letter. After that the first
the server is turned off, the second one is loaded and the same one is assigned
letter for the selected disk partition.
After all the above conditions are met, you can install
install MSCS software.
Installation procedure
The procedure is simple: first perform the installation on one node, and then
its completion - on the second. To install, you must register
be in a domain with administrative rights.
You must install the software on a local drive, not a shared drive. In progress
installation of software on the first server, you must specify the name under which the class
ter will be available to clients, the names of the disks intended for
use as shared resources, network cards and their purposes
communication (for communication with clients, for interconnection, or for both -
th), IP addresses and mask.
The installation procedure on the second server is similar, with the exception
It means that instead of forming a new cluster, you need to connect to
already existing.
Cluster administration
To administer the cluster, use the Cluster Admi program
nistrator. It can be installed on any of the nodes included
in a cluster and on an arbitrary workstation.
The program interface is very reminiscent of the control console interface.
with the loaded impression, but now the administrator of the
The ditch is not a cast of the MMC.
Cluster Administrator Window
The window consists of two parts. On the left side in the form of a tree-like structure
tours present cluster elements: groups, available resources,
network interfaces, nodes, etc. On the right - the contents of one or another
branches of the cluster tree structure.
There is a button on the toolbar that allows you to connect to
any cluster to manage it. Using the keyboard administrator
You can perform the following operations:
Create a new resource;
Create and modify a cluster resource group;
Manage network interfaces;
Manage the resources of each node separately;
Simulate a resource failure;
Stop the work of individual groups;
Move resources between groups.
Most functions are performed using wizard programs.
Since this book does not set itself the task of replacing the document
mentation, we will only briefly consider some operations.
Create a new resource group
When creating a new resource group, you must specify, in addition to its name,
get the preferred owner. The choice depends on the type of use
my cluster model. To achieve high availability, you can specify
both nodes as owners. When providing a "hot reserve"
the preferred owner must be the primary node.

Set a preferred resource group owner
Creating a new resource
In Microsoft Cluster Server, you can create resources from one of the following:
common types:
Distributed Transaction Coordinator;
File share;
General application;
General service;
Virtual root of Internet Information Server;
IP address;
Queue Server (Microsoft Message Queue Server);
Network name;
Physical disk;
Print spooler;
Timer service.

Adding a new resource
For example, if you want to add a new virtual root for
your Web server, you need to create a resource of type US Virtual Root.
Defining Resource Interdependencies
Obviously, cluster resources cannot be started at random
ok. Those services on which the work of others depends must
start earlier.
Determining Resource Load Dependencies
So, before making the virtual root of the Web server available
for users, it is necessary to perform at least two operations
radio: determine the disk on which the directory is physically located,
being the virtual root, and assign an IP address. Accordingly
but these two resources must be designated as defining ones for the virtual
al server.
Defining Resource Properties
Finally, after the resource loading sequence is set,
you can define the properties of the newly created resource. Properties window
varies significantly depending on the type of resource. For example, on
The figure shows the definition of the parameters of the virtual root of the server.
ra Web. The full path on the disk, the name under which
it will be available to clients, as well as the access type.

Defining specific resource parameters
Editing resource properties
The properties of any resource can be edited. For this you need
You can right-click the resource name and in the context menu
select a team Properties.
A dialog box similar to this will appear
shown in the figure.

Modification of properties f)ecvl)ca
In this dialog box you can change the following settings:
Resource name and description;
Possible owners of the resource (at the server level);
The sequence of loading services that affect the operation of the editor
timed resource;
Options for restarting a resource in case of failure;
Polling intervals;
Command line and launch options.
Functionality check
To check the functionality of the created resource group in the administration
The cluster nistrator provides the ability to simulate a failure. On the-
example, to check the functionality of the virtual root of the server
ra Web its execution is transferred to another node using a menu command.
Over the next few minutes, the administrator will see in the window Cluster
Administrator,
how the system recognizes the stop of the service, initiation
starts it on another node and, after starting all the defining ser-
visov, launches the selected resource. Customers will notice only a small
(one to two minutes) delay.
Although restart options can be edited, it is not recommended
reduce the performance check time, since small
pauses in operation can be regarded as a cluster failure.
Conclusion
Windows NT 5.0 inherited all the features from previous versions
ensuring uninterrupted operation. Failsafe support tools
durable disk volumes, support for uninterruptible power supplies
niya, improved version of the backup program successfully
complemented by cluster technologies.
There is no doubt that the listed possibilities, together with the sub-
hardware fault tolerance support allows us to speak
about Windows NT Server 5.0 as a server operating system, quite
unable to meet the needs of enterprises where it is required
high level of reliability.
By clicking on the "Download archive" button, you will download the file you need completely free of charge.
Before downloading this file, think about those good essays, tests, term papers, dissertations, articles and other documents that are lying unclaimed on your computer. This is your work, it should participate in the development of society and benefit people. Find these works and submit them to the knowledge base.
We and all students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
To download an archive with a document, enter a five-digit number in the field below and click the "Download archive" button
Similar documents
Socio-economic improvement of financial and economic activities. Strategic analysis of the enterprise's position. Analysis of the internal and external environment of the enterprise. Horizontal analysis of assets and liabilities of the balance sheet. Analysis of the income statement.
course work, added 12/22/2011
Economic analysis of economic activity. Analysis of the analytical balance sheet, financial stability of the organization, assets and liabilities of the balance sheet, quality of equity capital, fixed assets, accounts receivable and payable, income and expenses.
course work, added 01/23/2013
Brief economic characteristics and assessment of the results of activities of Kubros LLC. Composition and structure of sources of formation of the organization's property. Settlements with suppliers and customers, organization of cash transactions. Financial planning of the company.
practice report, added 12/24/2014
Analysis of the management and remuneration system. Enterprise management bodies and personnel management structure. Organization of economic work. Main indicators of financial and economic activity. Analysis of income and profit.
course work, added 09/14/2006
Assessment of the structure and dynamics of the enterprise’s property and the sources of its formation. The relationship between asset and liability indicators on the balance sheet. Analysis of liquidity and solvency, indicators of financial stability and the likelihood of bankruptcy of the enterprise.
course work, added 11/02/2011
The role of analysis of financial and economic activities in enterprise management. The composition and structure of the balance sheet of Elegia LLC, indicators for assessing its solvency and liquidity. Development of measures to stabilize the financial condition of the enterprise.
course work, added 12/20/2015
Description of the activities of the cargo port. Calculation of labor productivity, dynamics and structure of assets and liabilities of the balance sheet, wage fund. Assessment of indicators of the enterprise's solvency, efficiency of capital use, and creditworthiness.
course work, added 06/09/2015
The essence and methods of analyzing the financial condition of an organization. Characteristics and analysis of the balance sheet of Izumrud LLC, the structure of its assets and liabilities. Evaluating the income statement and business performance indicators.
course work, added 06/27/2012
Equipment failure can cause serious damage to an organization's operations. Therefore, the ARTI company has developed a set of measures to prevent possible breakdowns and reduce to a minimum the repair time for clients’ office equipment.
Regularpreventionequipment
When concluding a service contract, certified engineers carry out preventive maintenance on office equipment on a regular basis. According to experience, it is optimal to carry out preventive maintenance once a month, regardless of whether there were malfunctions in the operation of the devices or not. Our service plan involves assigning a permanent engineer who, like a personal doctor, knows the operating conditions of your equipment and its condition very well.
After each engineer’s visit, the results of the work performed and recommendations are activated and entered into our specialized information system. In the future, the collected data allows us to timely prepare proposals for modernizing the fleet. They also serve as the basis for providing our clients with detailed reports on the condition of equipment, work performed for any period of time and costs incurred for the maintenance of office equipment.
Forecasting breakdowns and planning replacement of resource spare parts
The Service Center information system is a tool for engineers to predict possible breakdowns and plan the optimal time to replace resource parts before equipment shutdown.
Well-established business processes for providing services in conjunction with an information system allows:
Quickly assess the level of load and wear of each specific device.
Predict as accurately as possible the need to replace resource parts.
Forecast for future periods the level of costs for maintaining equipment in working condition.
Provide analytical reports to the customer on a regular basis.
Credit scheme for replacement of consumables and spare parts
The ARTI service center provides consumables and spare parts on credit under a comprehensive service agreement. Payment is made upon replacement at the end of the reporting period based on the acts signed by the client. This allows you to minimize equipment downtime, reduce administrative costs and generally improve all company business processes related to the preparation of documents.
Advantages of using this scheme:
- Providing one detailed invoice (with all supporting documents) instead of dozens of invoices from different suppliers.
- Reduced equipment downtime associated with delays in payment of bills for consumables and spare parts.
- Pay only for what is actually used - unlike contracts with advance payment.
- Reducing administrative costs (housekeeping, IT and accounting departments) for interaction with various service organizations and saving time for your employees.
- Timely completion of all necessary work, as well as supply of original consumables and spare parts.